Annotation Module
Human-machine collaboration for corpus annotation
Overview
The Annotation Module provides an interface for collaborative corpus annotation, where language models assist linguists with labeling tasks while human experts provide quality control and domain expertise.
This creates a feedback loop:
- Language models help linguists by pre-annotating data and handling repetitive tasks
- Linguists correct model errors, creating high-quality training data
- Improved models benefit from linguistically-informed annotations
When to use it
- Correcting automatic NLP annotations (POS tags, NER, dependency parsing)
- Creating gold-standard training data for domain-specific models
- Annotating phenomena that require human judgment (pragmatics, discourse)
- Quality control for large-scale annotation projects
Annotation Interfaces
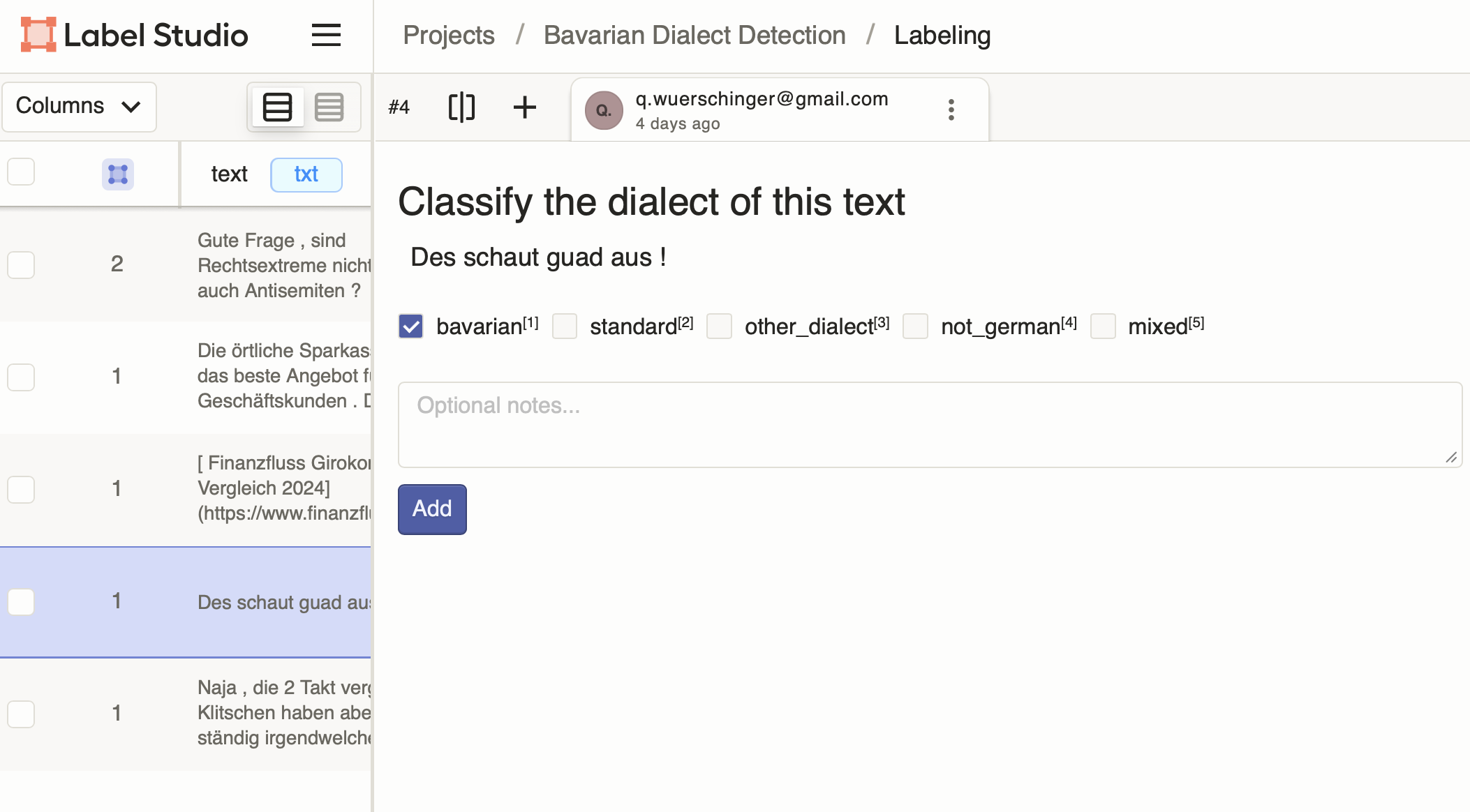
Language Identification (LID)
For multilingual corpora, verify or correct automatic language detection at the document or sentence level.
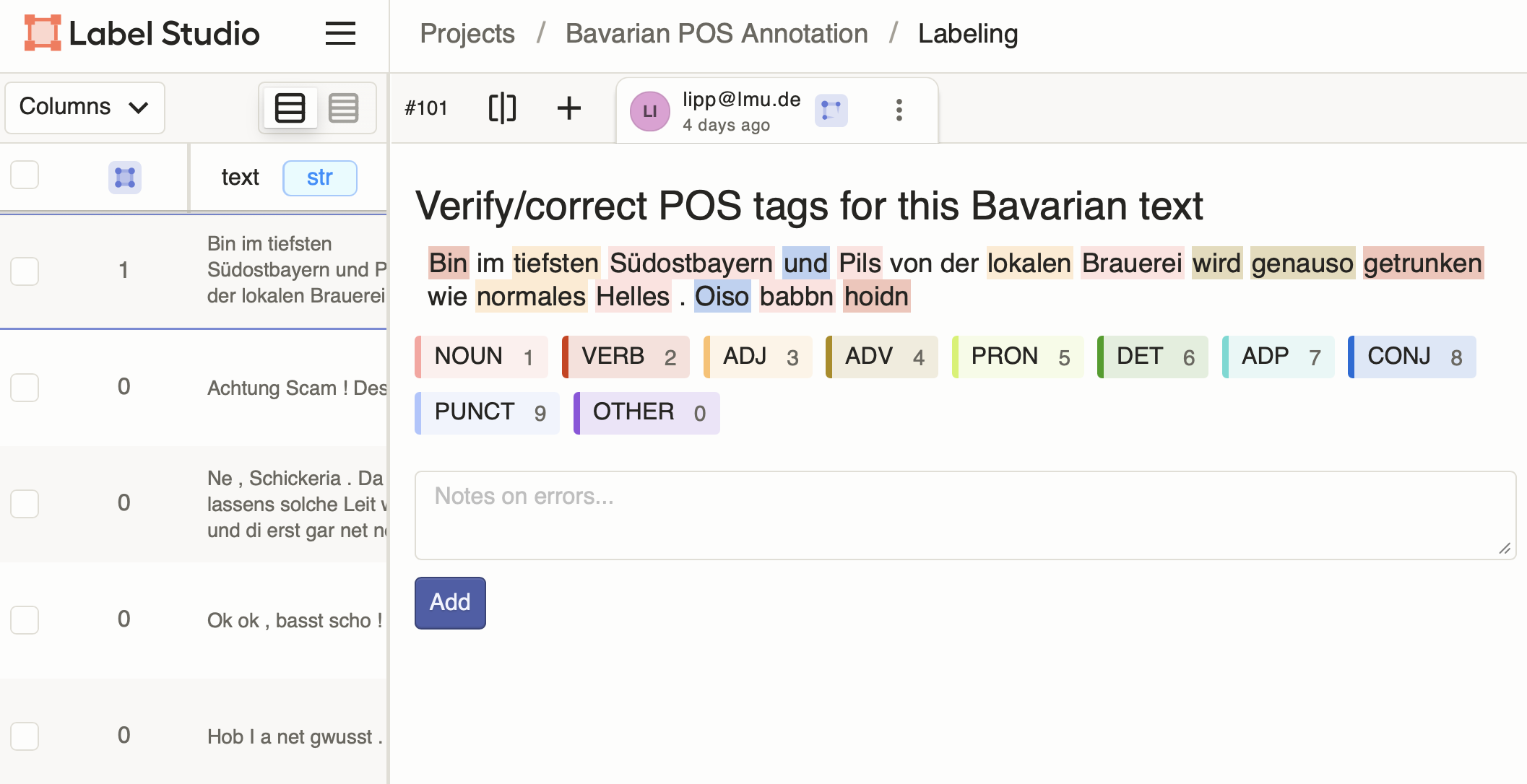
Part-of-Speech (POS) Tagging
Review and correct automatic POS annotations, particularly useful for:
- Non-standard varieties (dialects, historical texts, social media)
- Domain-specific terminology
- Ambiguous cases where context matters
How to run
- Select a corpus with annotation support in the custom app.
- Open the Annotation panel from the tools menu.
- Choose the annotation type (LID, POS, or custom).
- Review pre-annotated items and correct as needed.
- Submit annotations to update the corpus.
Output
- Corrected annotations stored in the corpus database
- Annotation statistics (agreement, corrections per session)
- Export of annotated data for training or analysis
Notes & tips
- Start with a small sample to calibrate your annotation guidelines.
- Use the keyboard shortcuts for faster annotation.
- Annotations can be exported as training data for fine-tuning models.
- Multiple annotators can work on the same corpus; inter-annotator agreement is tracked.
Why Annotation Matters: NLP Challenges for Non-Standard Varieties
Standard NLP tools trained on formal written language often fail on dialects, social media, and historical texts. The Annotation Module addresses these systematic errors.
Language Identification
Problem: Tools like fastText label dialect text as standard German:
| Variety | Example | fastText | GlotLID |
|---|---|---|---|
| Bavarian | wennst as ned saufst | de |
de_bavarian |
| Swiss German | Weiss eigetlech öpper wie das funktioniert? | de |
de_alemannic |
MCL uses GlotLID (Kargaran et al. 2023) for fine-grained dialect identification, but manual verification catches edge cases.
Lemmatization Failures
Problem: spaCy’s German model doesn’t normalize dialect words:
| Bavarian | spaCy Lemma | Expected |
|---|---|---|
| ned | ned | nicht |
| wos | wos | was |
| hoid | hoid | halt |
Impact: Lemma searches like [lemma="nicht"] miss dialect variants (ned, net, nit).
POS Tagging Errors
Problem: Dialect words are tagged as Named Entities (NE) or Foreign Material (FM):
| Standard German | Bavarian | spaCy Tag | Expected |
|---|---|---|---|
| weiß (know) | woaß | NE | VVFIN |
| ich (I) | i | NE | PPER |
| nicht (not) | ned | FM | PTKNEG |
Impact: POS-based queries like [tag="VVFIN"] miss dialect verbs.
Dependency Parsing Breakdown
For standard German, dependency parsing correctly identifies negation:
- nicht → head: möchte, deprel: ng (negation)
For Bavarian, the tree structure breaks down completely:
- ned → parsed as accusative object instead of negation marker
Improving NLP with Domain Adaptation
The MaiBaam benchmark (Blaschke et al. 2024) shows that even modern transformers struggle with Bavarian:
| Model | POS | LAS |
|---|---|---|
| UDPipe | 80.29% | 65.79% |
| mBERT | 78.74% | 54.96% |
| spaCy de_lg | 39.94% | 11.73% |
Domain-Adaptive Pre-Training (DAPT) (Gururangan et al. 2020) improves performance by adding dialect tokens:
| Model | POS | LAS |
|---|---|---|
| Modern mBERT | 78.19% | 49.28% |
| + DAPT (+1k Bavarian tokens) | 80.46% | 54.71% |
| Improvement | +2.27% | +5.43% |
Human annotation provides the gold-standard data needed for such improvements.
Research context
The Annotation Module embodies the convergence of linguistics and computational linguistics at the level of corpus data (Weissweiler, Köksal, and Schütze 2024). High-quality linguistic annotations improve NLP systems, while NLP pre-processing makes large-scale linguistic research feasible.