Munich Corpus Lab
Center for Information and Language Processing (CIS), LMU

Project Context
Motivation and Needs
The wants and needs of linguists:
- Expensive licenses for corpus platforms
- Using existing corpora outside of platforms/tools
- Creating corpora: e.g., modern data sources like Reddit, YouTube, and WhatsApp
- Analyzing corpora with current methods from NLP and LLMs (e.g., dependency parsing, topic modelling, sentiment analysis, embeddings, classification)
- Research data management: sharing, publishing, and archiving corpus linguistic data
Munich Corpus Lab
Needs and interest also at other LMU institutes:
- Linguistics: English, German, Slavic, Romance Studies
- Language Teaching: corpus-based language pedagogy, learner corpora
- Institute for Phonetics and Speech Processing (IPS): Phonetics and Speech Processing
maybe also: Center for Information and Language Processing (CIS)
Goal: collaborative, modern, sustainable corpuslinguistic work.
- Providing and integrating corpora for research and teaching
- Modern data sources: Reddit, YouTube, web corpora
- Integration of AI and NLP methods: dependency parsing, topic modelling, semantic analysis with embeddings, LLM classifications
- Application Interface for linguistics across philologies and methodological disciplines (e.g. CIS & IPS)
First step: developing an app to explore potential.
The Munich Corpus Lab App
https://www.wuerschinger.org/mcl
Username: lipp@lmu.de
Password: Sch3ll!ng1860
Backend: No Sketch Engine
React frontend
No Sketch Engine frontend
Current corpora on the Munich Corpus Lab
- COHA (Davies 2012): Corpus of Historical American English, 1820–2019, 475M tokens. Genre-balanced: newspapers, magazines, fiction, academic texts.
- COCA (Davies 2010): Corpus of Contemporary American English, 1990–present, 560M tokens. Genre-balanced: newspapers, magazines, fiction, academic texts, TV/film.
- Stream (Benker): English YouTube transcripts, three channels (Entertainment, Commentary), ~15M tokens.
- ICE-Bahamas (Hackert 2010): International Corpus of English – Bahamas component, 50K tokens. Variety research in Caribbean English.
- UniPlans (Kersten): English strategic plans from 50 universities worldwide, 2020–2024, 383K tokens. Institutional discourse and higher education policy.
- enRed: English Reddit discussions from regional subreddits (r/Wales, r/Scotland, r/northernireland, r/AskUK, r/AskAnAmerican), 1.47B tokens, 2010–2024. Variety research.
- ruRed: Russian Reddit discussions (r/Pikabu, r/AskARussian), 215M tokens. Informal online communication.
- fRed: French Reddit discussions from Quebec, France, and Belgium (r/Quebec, r/rance, r/Belgium2), 272M tokens.
- skRed: Slovak Reddit discussions from 5 subreddits (r/Slovakia, r/Slovensko, etc.), 67M tokens. UDPipe annotation.
- GeRedE (FAU): German Reddit discussions from 11 subreddits (Austria, ich_iel, Finanzen, etc.), 51M tokens, 2010–2018. Informal online communication.
A German Dialect Reddit Corpus
Overview
Reddit: Social media platform with topical communities (subreddits). (Baumgartner et al. 2020).
174M tokens from 17 subreddits (2008–2024)
| Subreddit | Tokens |
|---|---|
| r/de | ~33M |
| r/Finanzen | ~27M |
| r/Austria | ~19M |
| r/de_EDV | ~16M |
| r/FragReddit | ~14M |
| r/Switzerland | ~13M |
| r/wien | ~12M |
| r/Munich | ~11M |
| r/fcbayern | ~8M |
| Subreddit | Tokens |
|---|---|
| r/hamburg | ~6M |
| r/FinanzenAT | ~6M |
| r/graz | ~4M |
| r/BUENZLI | ~2M |
| r/ich_iel | ~2M |
| r/aeiou | ~1M |
| r/okoidawappler | ~1M |
| r/bavaria | ~1M |
Overview of features
All features of Sketch Engine:
- Query Builder
- Concordances
- Linguistic attributes
- Sentence segmentation
- Lemmatization
- POS tagging
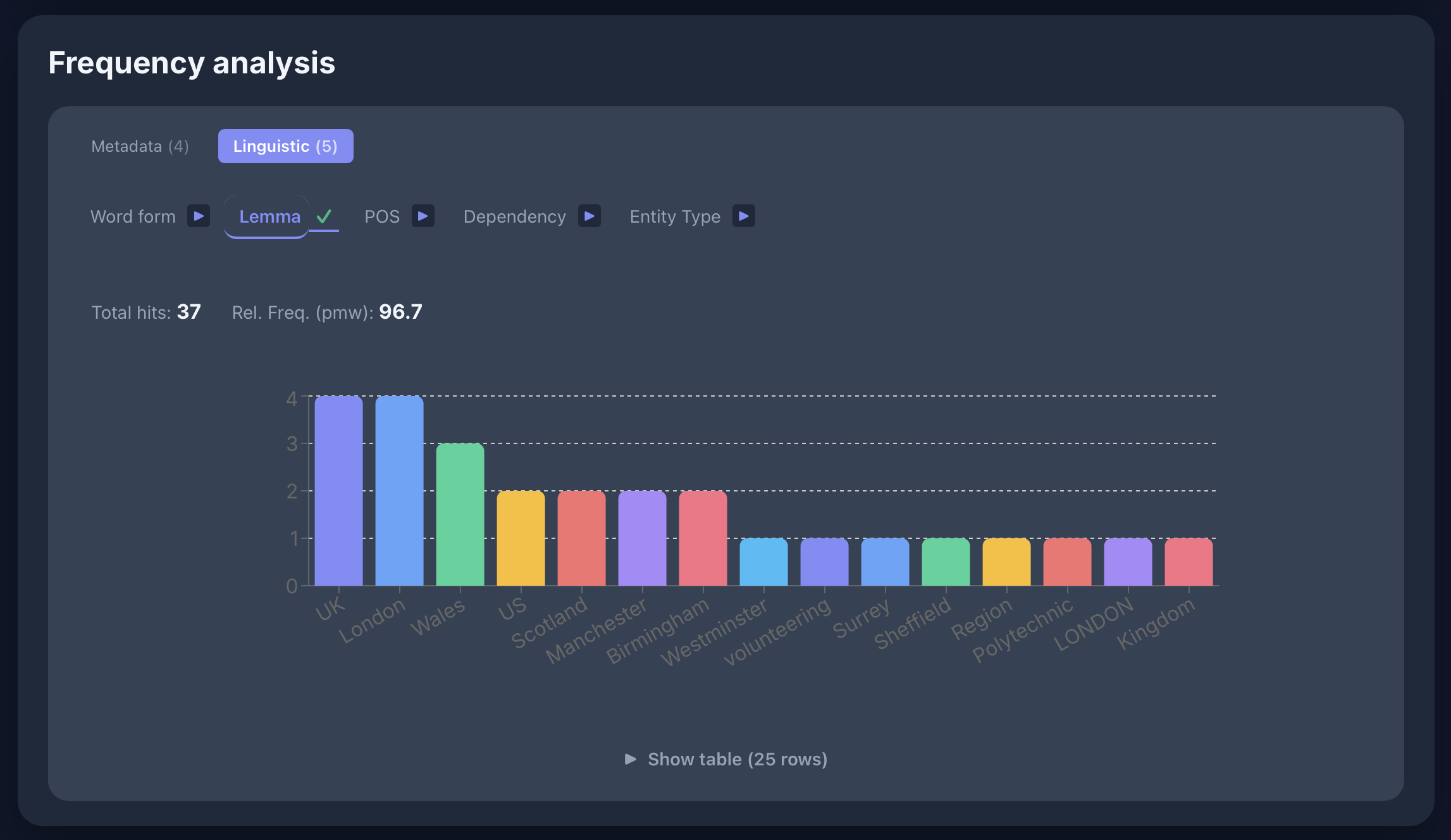
- Frequency analysis
- Collocation analysis
Excluded: Word Sketches, Ngrams, and Thesaurus
Additional features:
- Linguistic attributes
- Dependency Parsing
- Morphological Parsing
- Named Entity Recognition
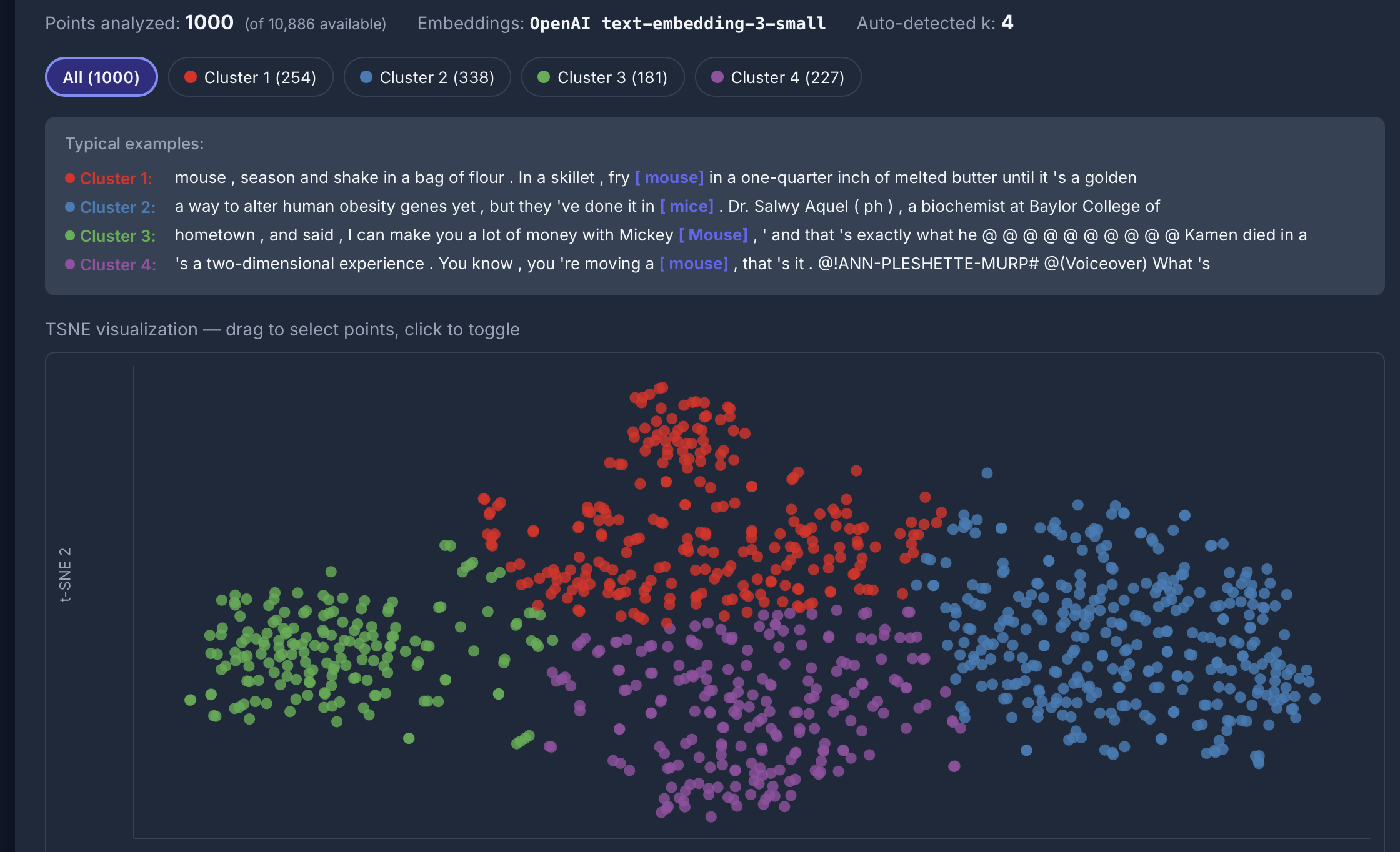
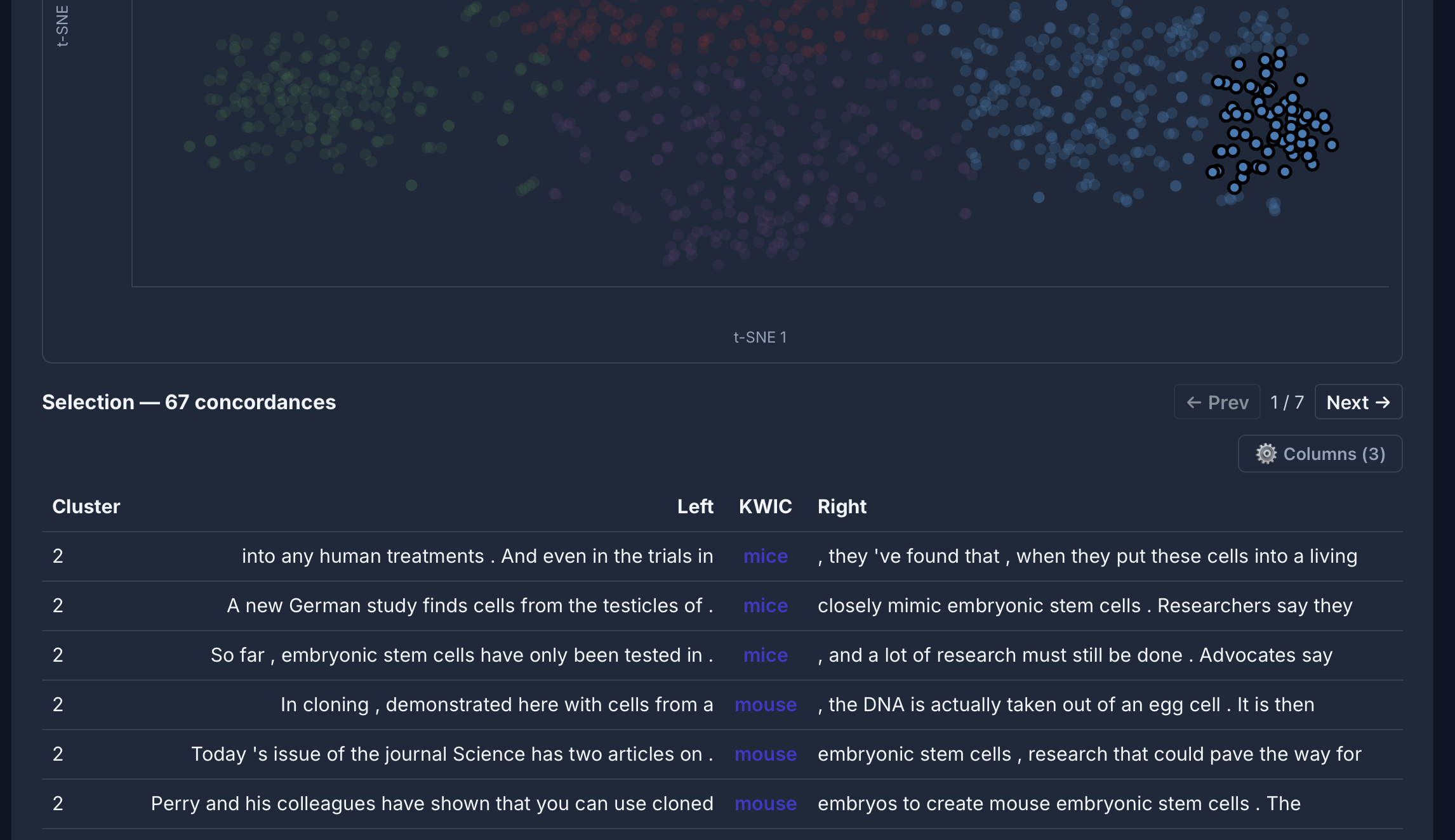
- Semantic analysis based on embeddings
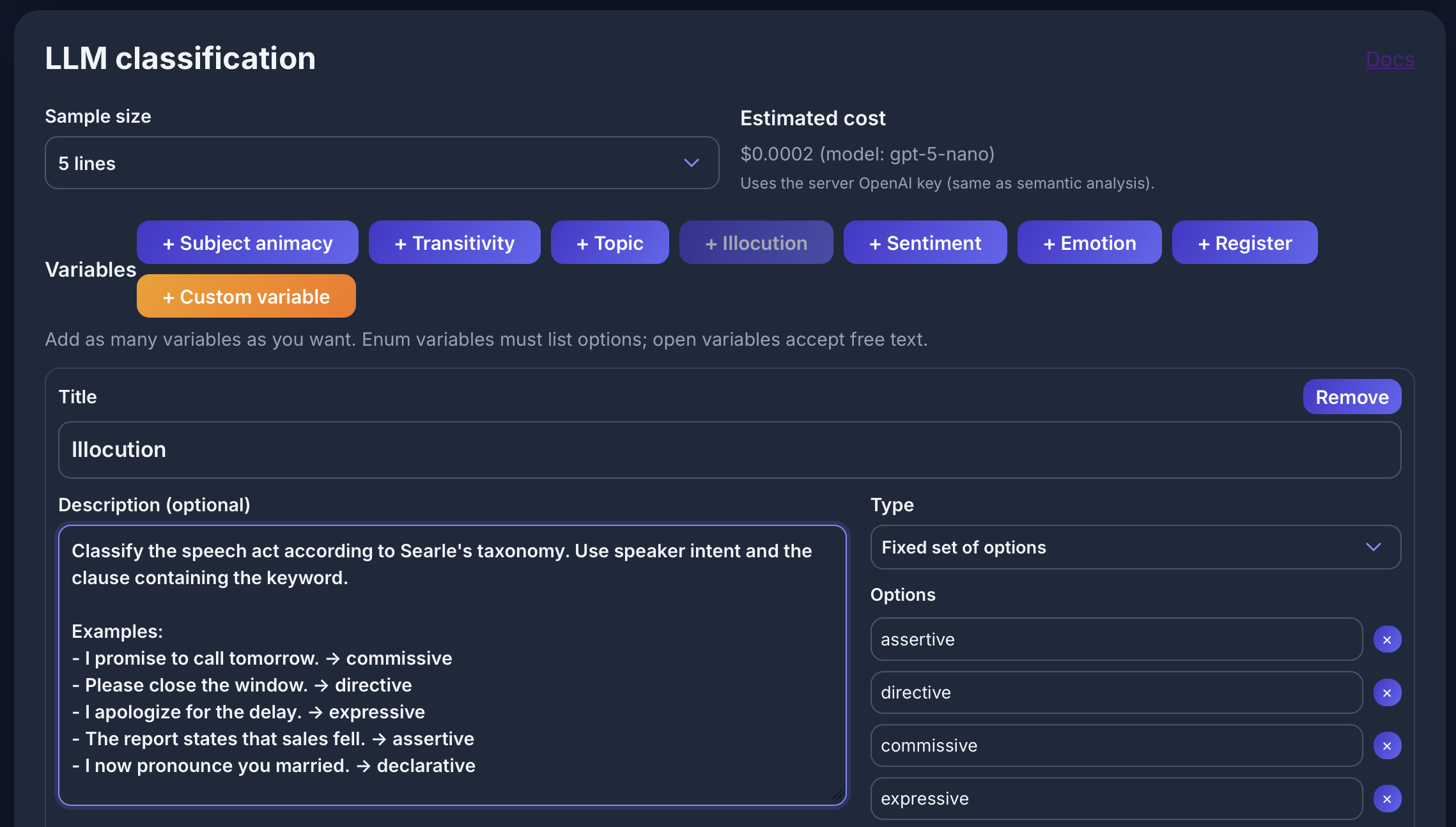
- Classification of corpus data with LLMs
- Social Network Analysis
- Full data export
- API for Python and R
- Documentation for features and corpora
Linguistic Features
NLP annotation with spaCy de_core_news_lg (Honnibal et al. 2020):
| Attribute | Query | Finds |
|---|---|---|
word |
[word="München"] | München (exact form) |
lemma |
[lemma="sein"] | ist, sind, war, waren, bin … |
tag |
[tag="VERB"] | all verbs |
deprel |
[deprel="nsubj"] | subjects: ich, es, er, München … |
morph |
[morph=".Case=Dat."] | dative: dem, der, mir, dir … |
ent_type |
[ent_type="PER"] | persons: Söder, Merkel, Scholz … |
Metadata
27 document attributes:
- Basic:
subreddit,author,date,year - Language (GlotLID (Kargaran et al. 2023)):
lang: ISO code (de, gsw, bar, en)lang_group: language family (german, swiss_german, bavarian)lang_conf: confidence (0–1)
- Social Network Analysis:
parent_id: parent comment → reply networkslink_id: thread ID → discussion structuresscore: upvotes → influence weighting
- Engagement:
controversiality,gilded,num_comments - Context:
title,post_flair(Politics, Meme, Question)
Query Builder

Concordance View
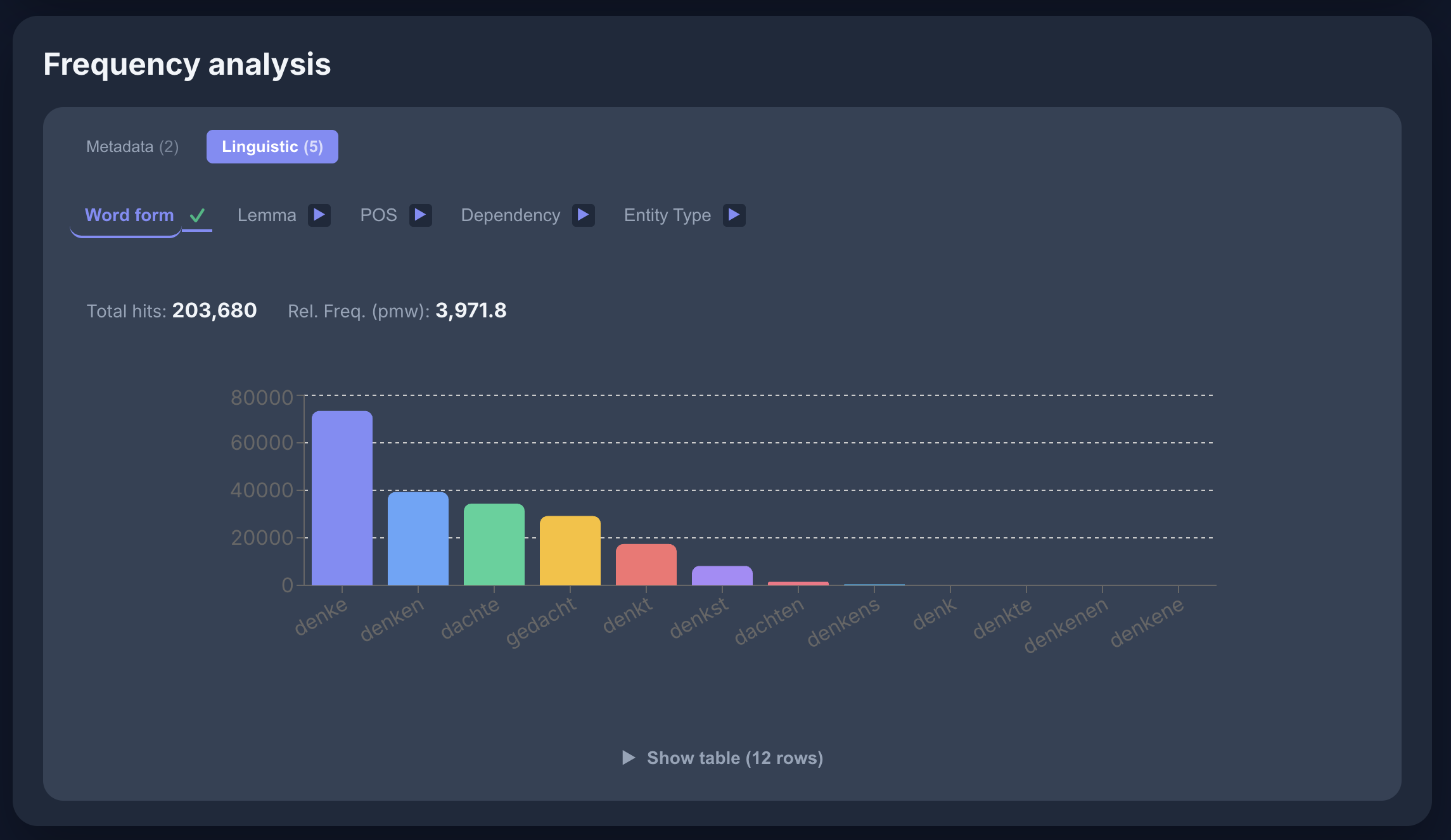
Frequency Analysis
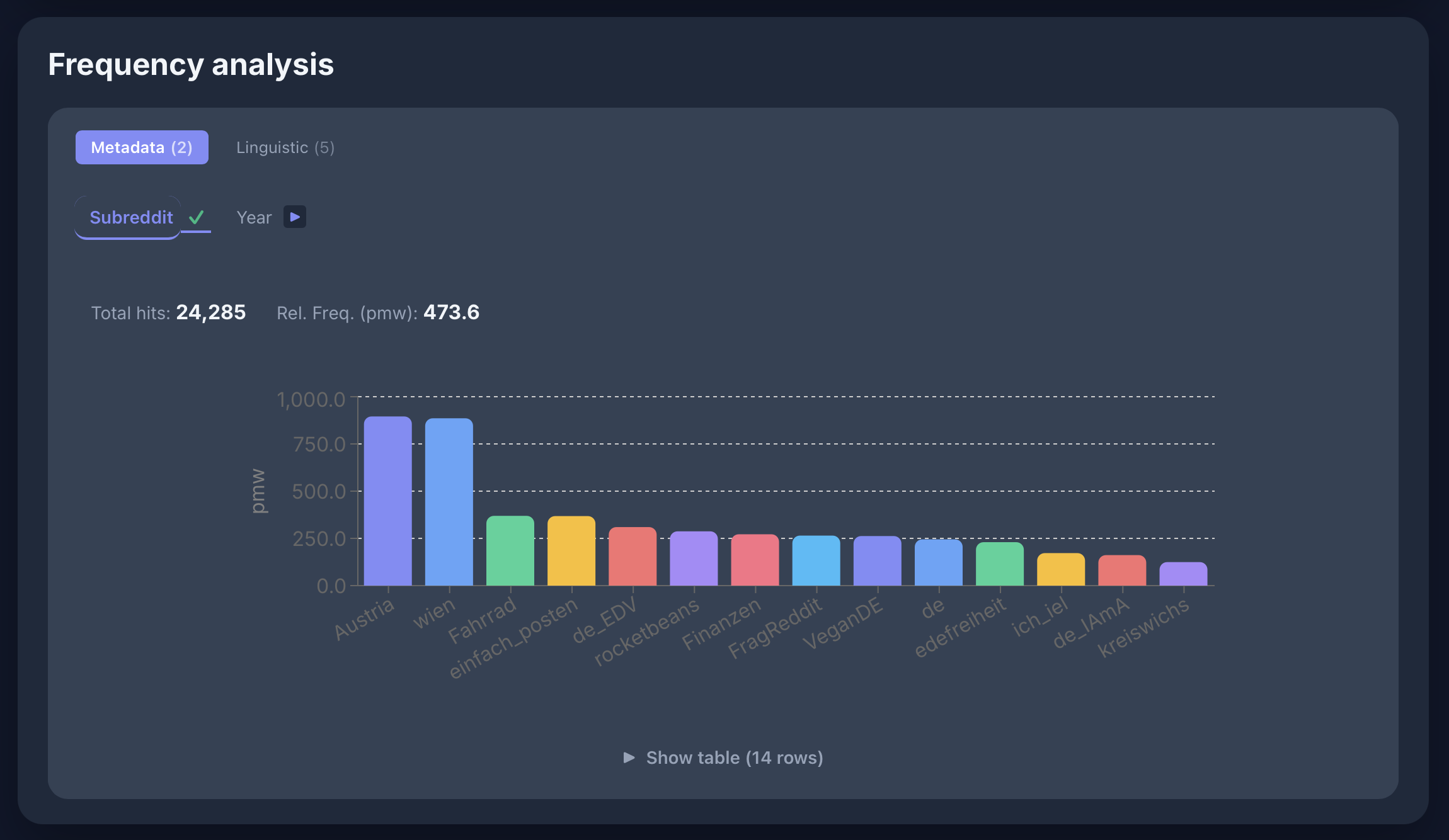
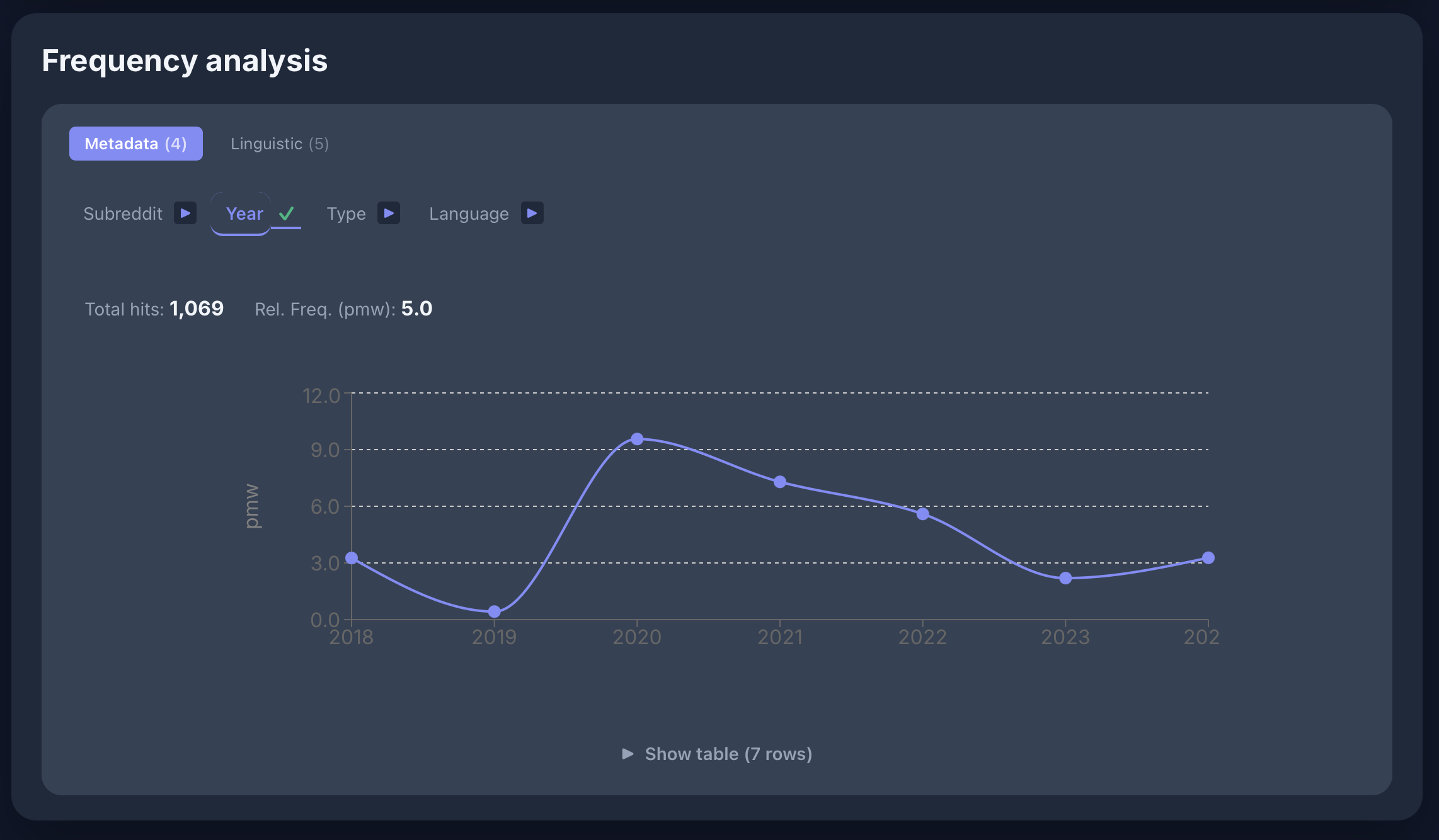
Dependencies
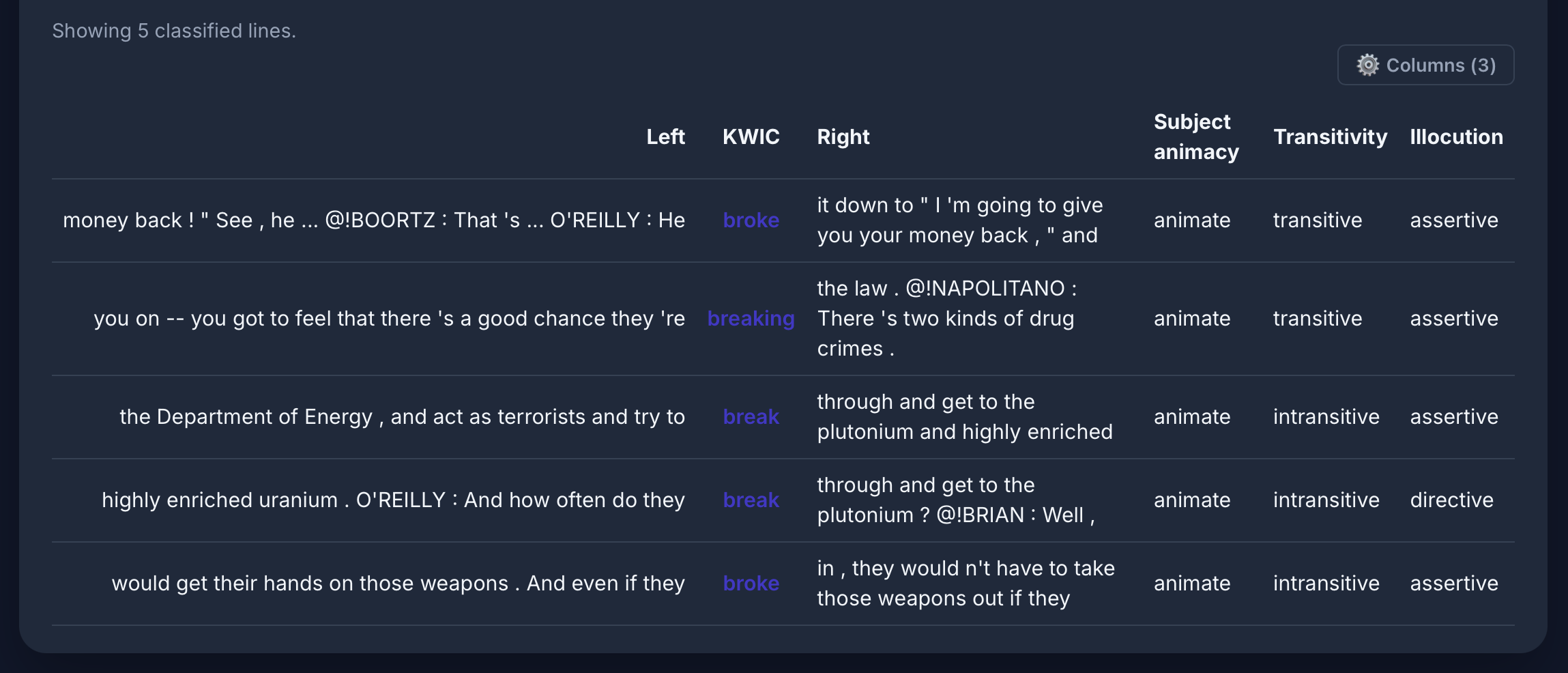
[lemma="Mensch" & deprel="da"] [tag="VVFIN"] in the GeRedE corpus:
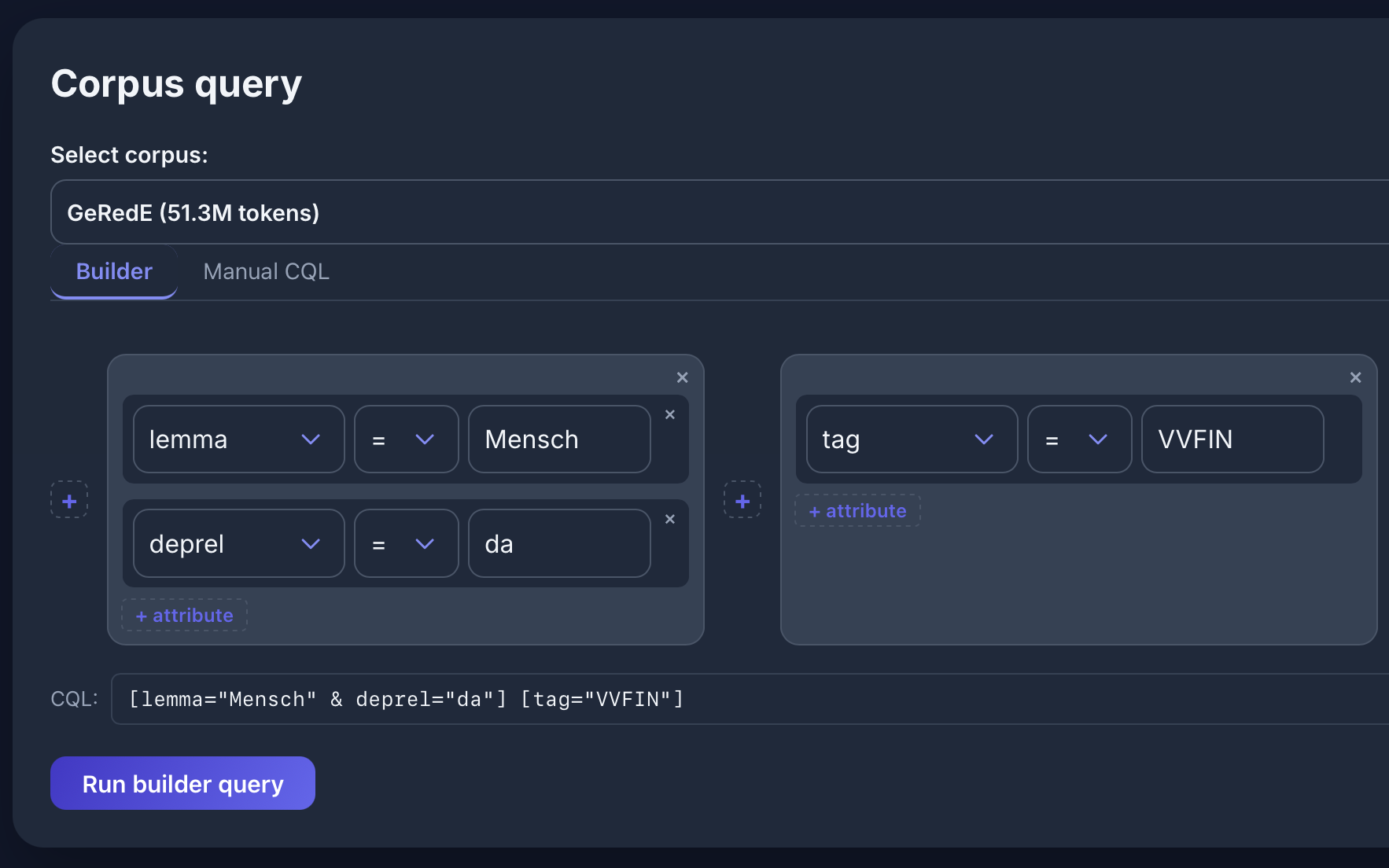
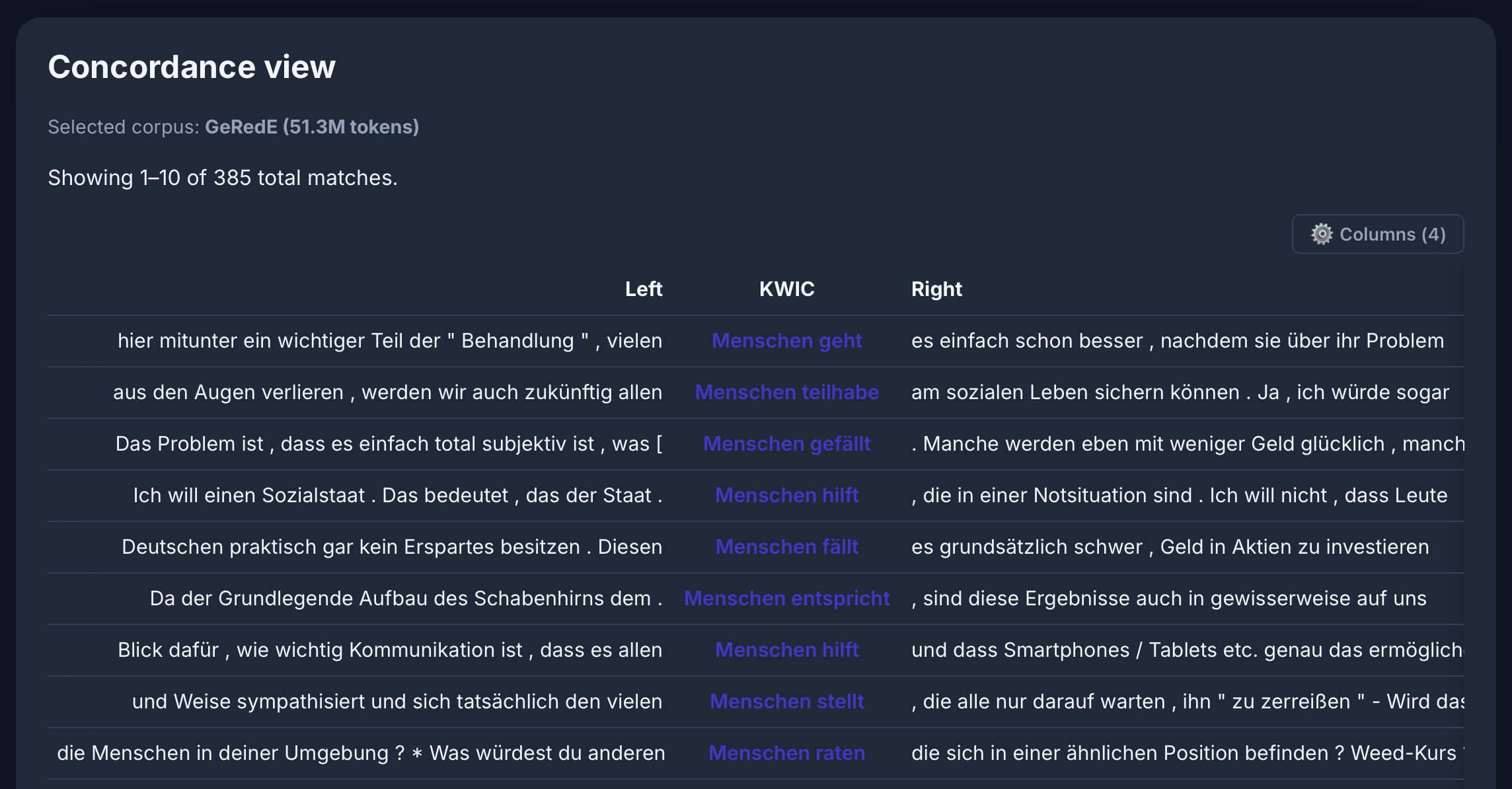
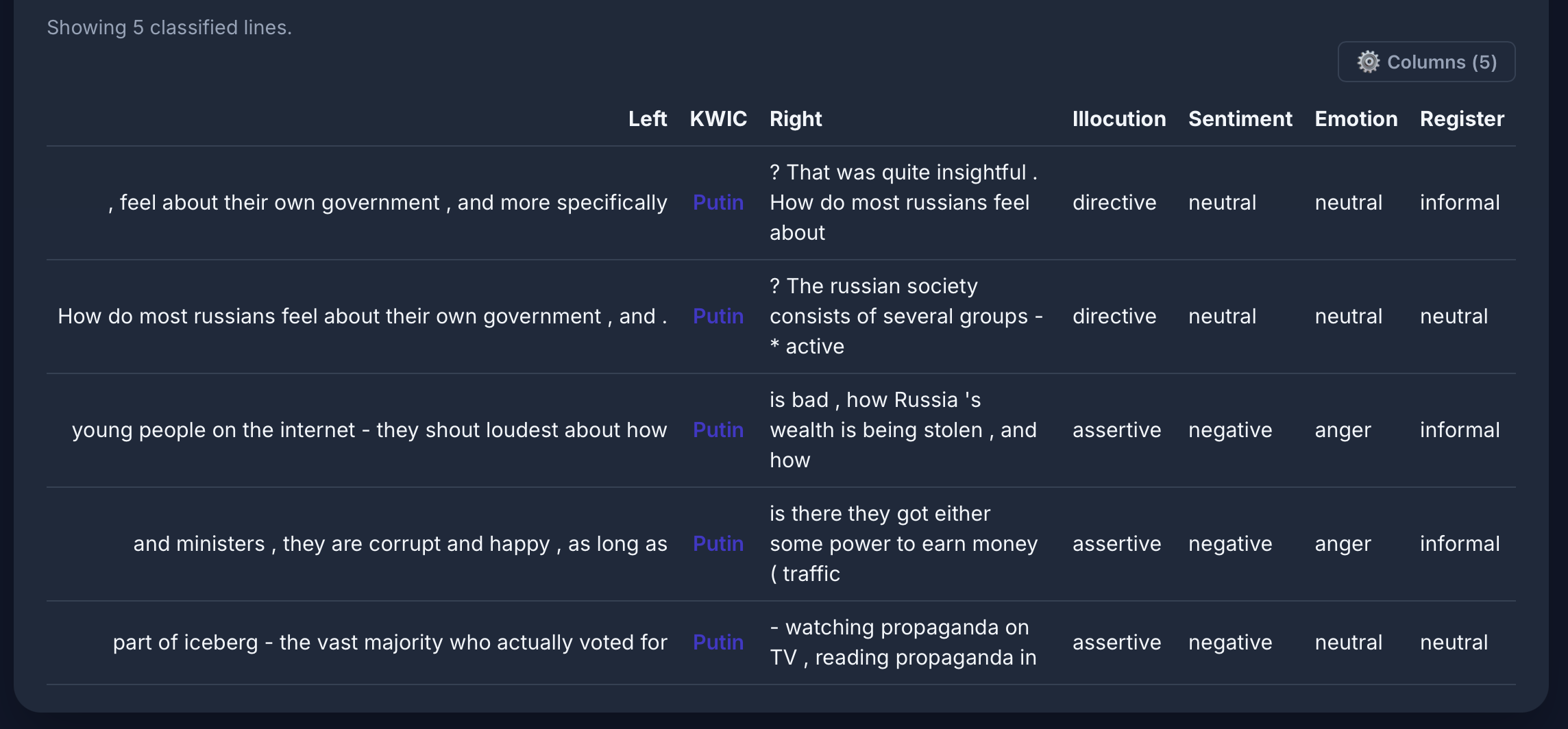
Named Entities
Semantic analysis
LLM classification
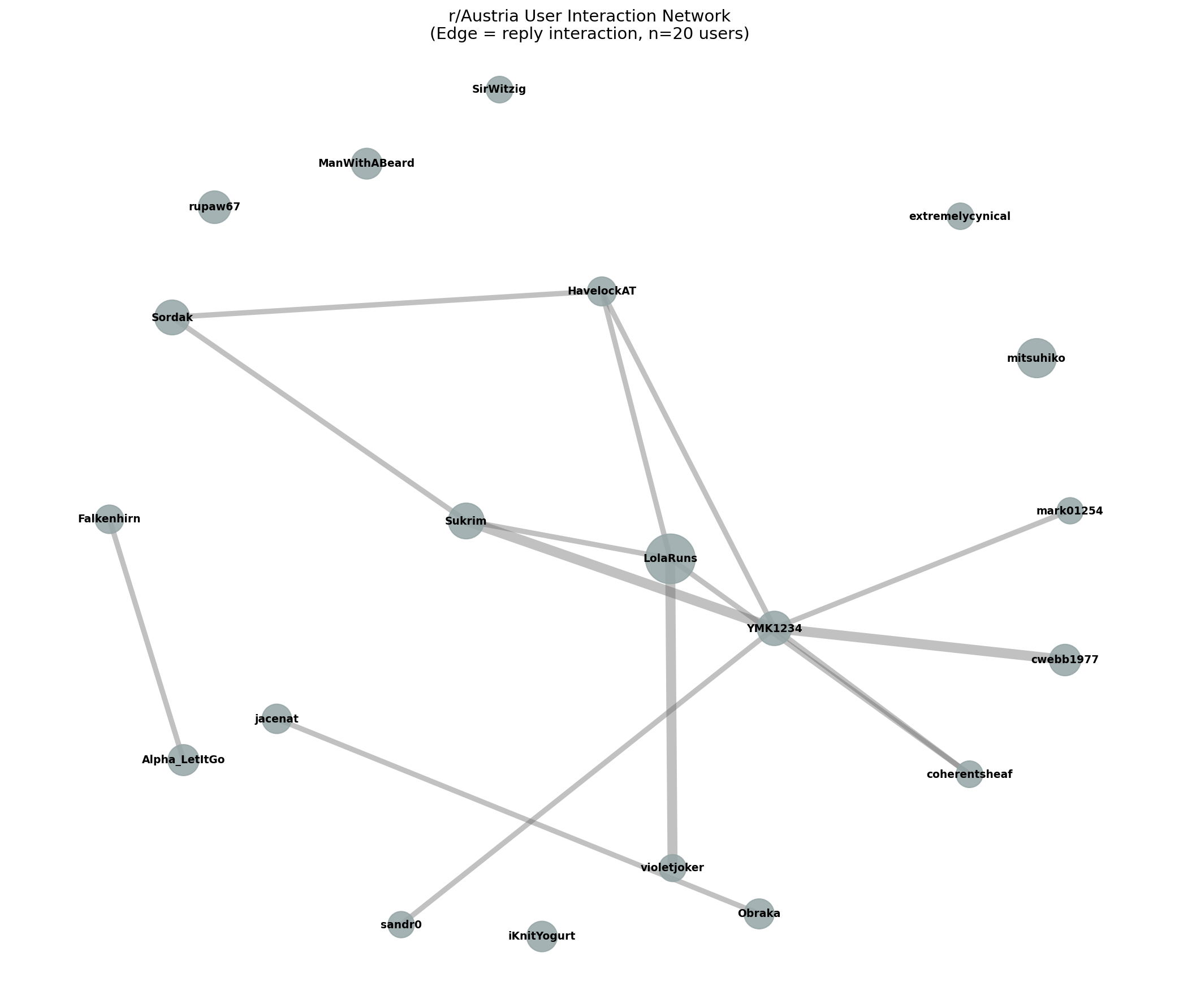
User Interaction Network (r/Austria)
Challenges in the area of Computational Linguistics
Language identification
Languages
Language identification with fastText (Joulin et al. 2017):
| Language | Tokens | % |
|---|---|---|
| German (de) | ~130M | 74.58% |
| English (en) | ~41M | 23.28% |
| (unidentified) | ~3M | 1.98% |
| French (fr) | ~119K | 0.07% |
| Dutch (nl) | ~42K | 0.02% |
| Italian (it) | ~34K | 0.02% |
| Portuguese (pt) | ~29K | 0.02% |
Less than 0.01% for the following languages:
Polish (pl), Luxembourgish (lb), Slovenian (sl), Spanish (es), Slovak (sk), Hungarian (hu)
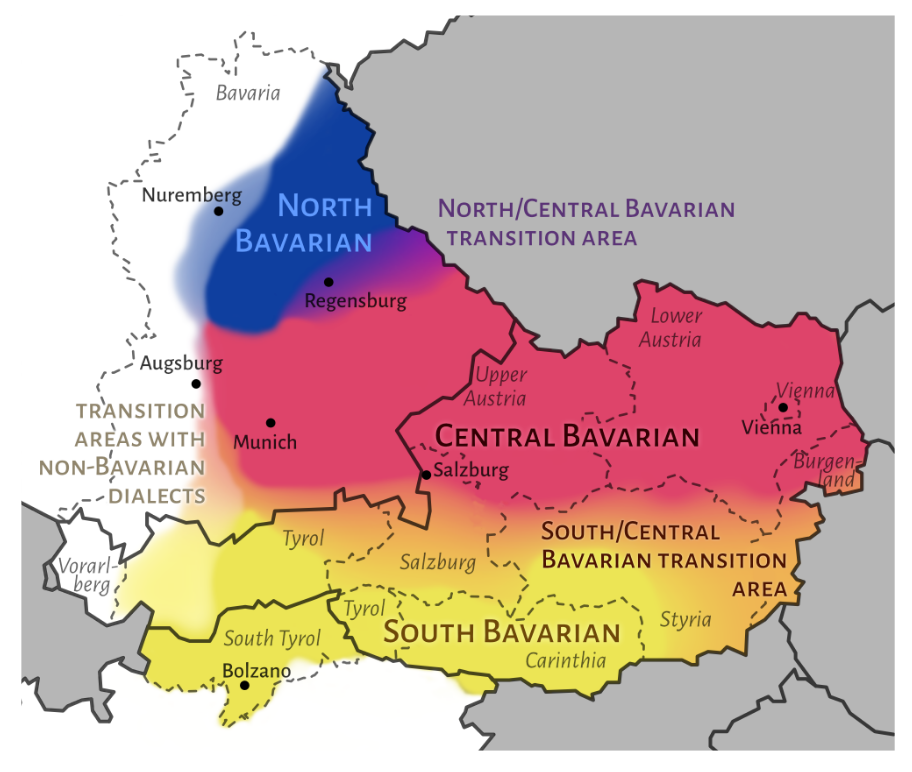
Dialects in the corpus
Problem: fastText labels dialect text as standard German (de):
Bavarian (r/aeiou, r/okoidawappler):
- wennst as ned saufst kannst a ned mitreden
- Muaßt hoid a Gambrinus drinkn
→ fastText: de ✗
Swiss German (r/BUENZLI):
- Wer dä Lappe nöd ehrt isch dä Schnegg nöd wert
- Weiss eigetlech öpper wie das z’Bärn funktioniert?
→ fastText: de ✗
Using GlotLID (Kargaran et al. 2023) for fine-grained dialect identification:
| Variety | Tokens | % | Notes |
|---|---|---|---|
| Standard German | ~127M | 72.90% | r/de, r/Finanzen |
| Alemannic (Swiss) | ~2M | 1.10% | r/BUENZLI |
| Bavarian | ~433K | 0.25% | r/okoidawappler, r/aeiou |
| Low German | ~6K | <0.01% | r/hamburg |
Bavarian (r/aeiou, r/okoidawappler):
- wennst as ned saufst kannst a ned mitreden
- Muaßt hoid a Gambrinus drinkn
→ fastText: de ✗ | GlotLID: de_bavarian ✓
Swiss German (r/BUENZLI):
- Wer dä Lappe nöd ehrt isch dä Schnegg nöd wert
- Weiss eigetlech öpper wie das z’Bärn funktioniert?
→ fastText: de ✗ | GlotLID: de_alemannic ✓
Lemmatization
spaCy de_core_news_lg (Honnibal et al. 2020) — trained on Standard German, struggles with dialects:
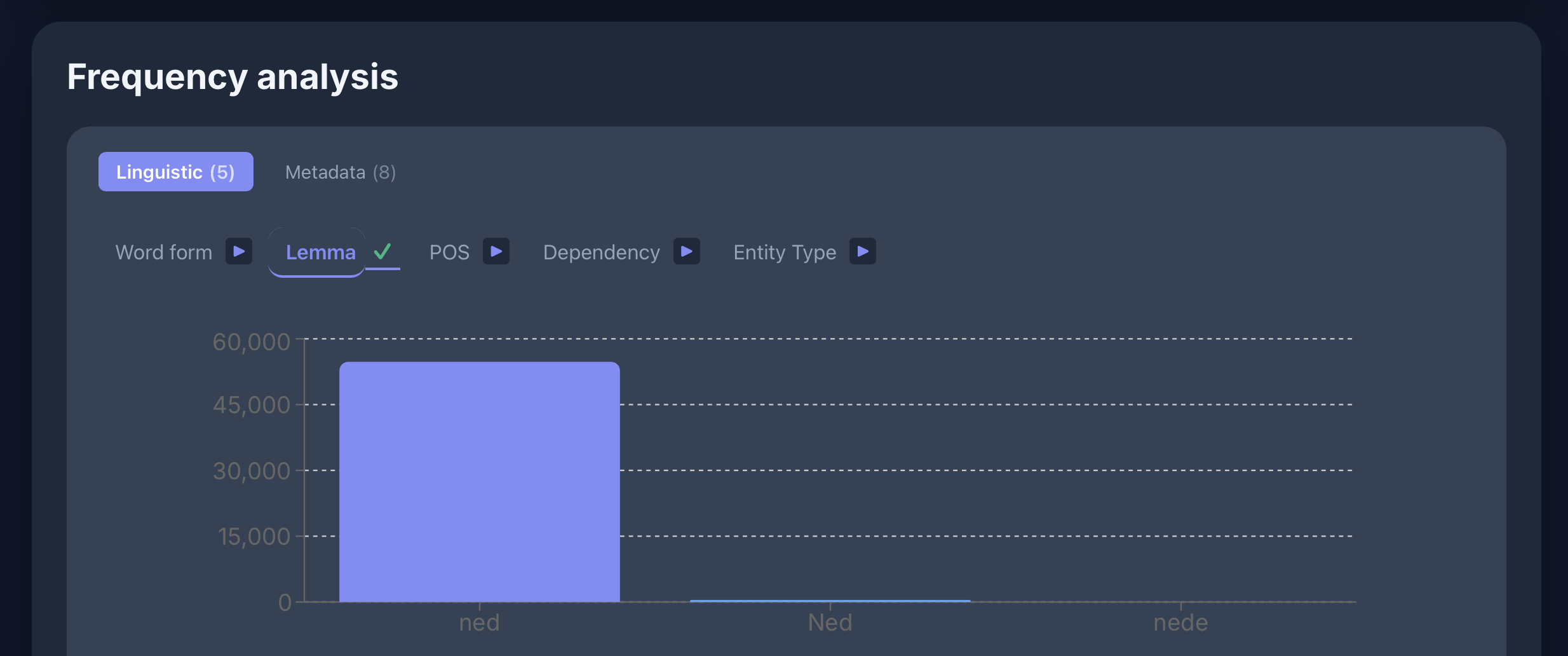
Standard German → spaCy:
| Word | Lemma | |
|---|---|---|
| nicht | nicht | ✓ |
| was | was | ✓ |
| halt | halt | ✓ |
Bavarian → spaCy:
| Word | Lemma | Expected | |
|---|---|---|---|
| ned | ned | nicht | ✗ |
| wos | wos | was | ✗ |
| hoid | hoid | halt | ✗ |
POS tagging
Standard German → spaCy:
das weiß ich halt nicht
| Word | Tag | |
|---|---|---|
| das | PDS | ✓ |
| weiß | VVFIN | ✓ |
| ich | PPER | ✓ |
| halt | ADV | ✓ |
| nicht | PTKNEG | ✓ |
Bavarian → spaCy:
des woaß i hoid ned
| Word | Tag | Expected | |
|---|---|---|---|
| des | PDS | PDS | ✓ |
| woaß | NE | VVFIN | ✗ |
| i | NE | PPER | ✗ |
| hoid | NE | ADV | ✗ |
| ned | FM | PTKNEG | ✗ |
Problem: Dialect words tagged as NE (Named Entity) or FM (Foreign Material)
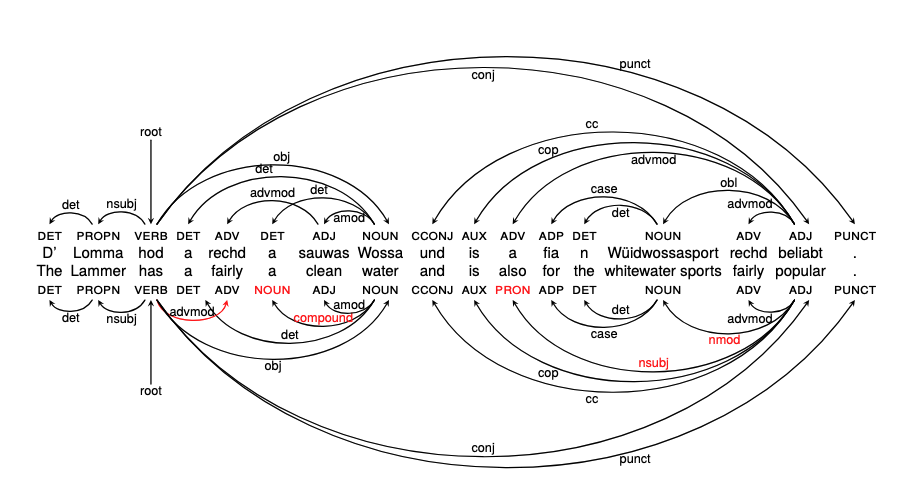
Dependency Parsing
Standard German:

| Word | Head | DepRel | |
|---|---|---|---|
| nicht | möchte | ng (negation) | ✓ |
| ich | möchte | sb (subject) | ✓ |
| begegnen | möchte | oc (inf. compl.) | ✓ |
Bavarian:

| Word | POS | DepRel | Expected | |
|---|---|---|---|---|
| mecht | PROPN | ROOT | AUX | ✗ |
| i | X | punct | PRON/sb | ✗ |
| ned | X | oa (acc.) | ng | ✗ |
Problem: ned parsed as accusative object — tree structure completely broken.
MaiBaam (Blaschke et al. 2024)
Best models:
| Model | POS | LAS | UAS |
|---|---|---|---|
| UDPipe | 80.29 | 65.79 | 79.60 |
| mBERT | 78.74 | 54.96 | 66.38 |
| GBERT | 74.68 | 50.57 | 62.67 |
Our replication:
| Model | POS | LAS | UAS |
|---|---|---|---|
| UDPipe | 80.25 | 64.78 | 79.77 |
| mBERT | 79.75 | 54.09 | 65.78 |
| GBERT | 73.64 | 48.48 | 61.19 |
| spaCy de_lg | 39.94 | 11.73 | 24.60 |
Have newer transformers become better at this?
Using MaChAmp (Goot et al. 2021) with Modern mBERT (Marone et al. 2025) and Modern GBERT (Wunderle et al. 2025):
| Model | POS | UAS | LAS |
|---|---|---|---|
| mBERT | 79.75 | 65.78 | 54.09 |
| Modern mBERT | 78.19 | 61.60 | 49.28 |
| GBERT | 73.64 | 61.19 | 48.48 |
| Modern GBERT | 67.66 | 54.70 | 40.29 |
→ Newer transformers seem to perform worse on Bavarian?
Is this a tokenization problem?
| Word | mBERT | ModernGBERT |
|---|---|---|
| wos | wos |
wo + ##s |
| gsagt | g + ##sagt |
g + ##sa + ##gt |
| kemma | ke + ##mma |
ke + ##mm + ##a |
→ German-specific models fragment Bavarian more aggressively
Can we improve this by adding Bavarian tokens and domain adaptation?
Adding 1k Bavarian tokens (ned, wos, hoid, oiwei, dahoam, gsagt, …)
+ Domain-Adaptive Pre-Training (Gururangan et al. 2020) on the Bavarian Reddit data:
| Model | POS | UAS | LAS |
|---|---|---|---|
| Modern mBERT | 78.19 | 61.60 | 49.28 |
| + DAPT | 80.46 | 65.82 | 54.71 |
| Δ | +2.27 | +4.22 | +5.43 |
| Modern GBERT | 67.66 | 54.70 | 40.29 |
| + DAPT | 71.16 | 57.06 | 44.01 |
| Δ | +3.50 | +2.36 | +3.72 |
→ DAPT improves dialect handling, but the overall results are still underwhelming.
Problems
Even with DAPT, models still struggle with Bavarian:
Lemmatization
| Input | Output | Expected | |
|---|---|---|---|
| koa | koa | kein | ✗ |
| nix | nix | nichts | ✗ |
| oba | oba | aber | ✗ |
| heid | heid | heute | ✗ |
POS Tagging
| Input | Output | Expected | |
|---|---|---|---|
| fei | ADV | PART | ✗ |
| geh | VERB | PART | ✗ |
| scho | ADJ | ADV | ✗ |
| oba | NOUN | CCONJ | ✗ |
Dependencies
| Input | Output | Expected | |
|---|---|---|---|
| i | nsubj | nsubj | ✓ |
| fei | advmod | discourse | ✗ |
| begenen | ROOT | xcomp | ✗ |
What is needed?
- better tokenization?
- more high quality data?
- more high quality annotations?
Annotation
Linguistics and Computational Linguistics meet at the level of corpus data.
- Language models can help linguists with annotation and tackling linguistic RQ (Weissweiler, Köksal, and Schütze 2024)
- Linguistic annotations and insights can inform NLP approaches and model development.
→ an application interface for collaboration between humans and machines
An interface between people and institutes at LMU.

Next Steps
Integration of Additional Corpora
- Project Gutenberg: Multilingual public domain fiction, 70k+ books in 60+ languages. Historical and literary language research.
- German Reddit Corpus: Expansion to comprehensive coverage (10M+ documents) in collaboration with Prof. Bülow
- ICE Bahamas: Expansion to comprehensive coverage as part of Prof. Hackert’s DFG project (Hackert 2010)
- BNC 2014: British National Corpus, spoken language (Love et al. 2017)
- TV/Movie Corpus (Davies 2021): English film and TV subtitles, 325M words, 1950–2018
- TokPisin: Tok Pisin corpus in collaboration with Prof. Hackert (Papua New Guinea creole language)
- YouTube Corpus: Automatic transcription and IPA annotation in collaboration with IPS (WebMAUS: Kisler, Schiel, and Sloetjes (2012))
- EEBO: Early English Books Online, 765M words, 1470s–1690s (Text Creation Partnership 2015)
- ARCHER: A Representative Corpus of Historical English Registers, 1600–1999 (Biber, Finegan, and Atkinson 1994)
Features in Development
- Annotation Module: Annotation of concordances with human-machine collaboration and active learning.
- RAG: Retrieval-Augmented Generation for Digital Humanities research questions.
- Topic Modelling: Topic modelling of corpus data with LLMs
- Social Network Analysis UI: Visualization of reply networks, author interactions
- Dependency Query Builder: Interactive UI for syntactic queries
- Semantic Tags: Categorization by semantic fields (Wmatrix: Rayson (2008))
- Transcription: Automatic transcription for YouTube and audio data (WebMAUS: Kisler, Schiel, and Sloetjes (2012))
- AI Mode: LLM-copilot for corpus analyses
Conclusion
Conclusion
- We see strong potential of a joint Corpus Lab for several institutes of Linguistics.
- There is also interest from other institutes like Digital Humanities, Phonetics (IPS), and Language Teaching.
- For sustainable project development, long-term resources will be needed for:
- Development & maintenance of the app (pre-processing, features, corpora, etc.),
- infrastructure (server, authentication system, databases, etc.),
- and services for processing new data and analyses.
Discussion
- How could the CIS benefit from such a Corpus Lab? Where do you see potential synergies?
- If so, are there specific methods, or linguistic data that would be of particular interest?
- Ideas for further development and institutional organization?
Social Network Analysis
Subreddit Network