Munich Corpus Lab
Slavische Sprachwissenschaft, LMU München

Die Munich Corpus Lab App
https://www.wuerschinger.org/mcl
Benutzername: lipp@lmu.de
Passwort: Sch3ll!ng1860
React interface
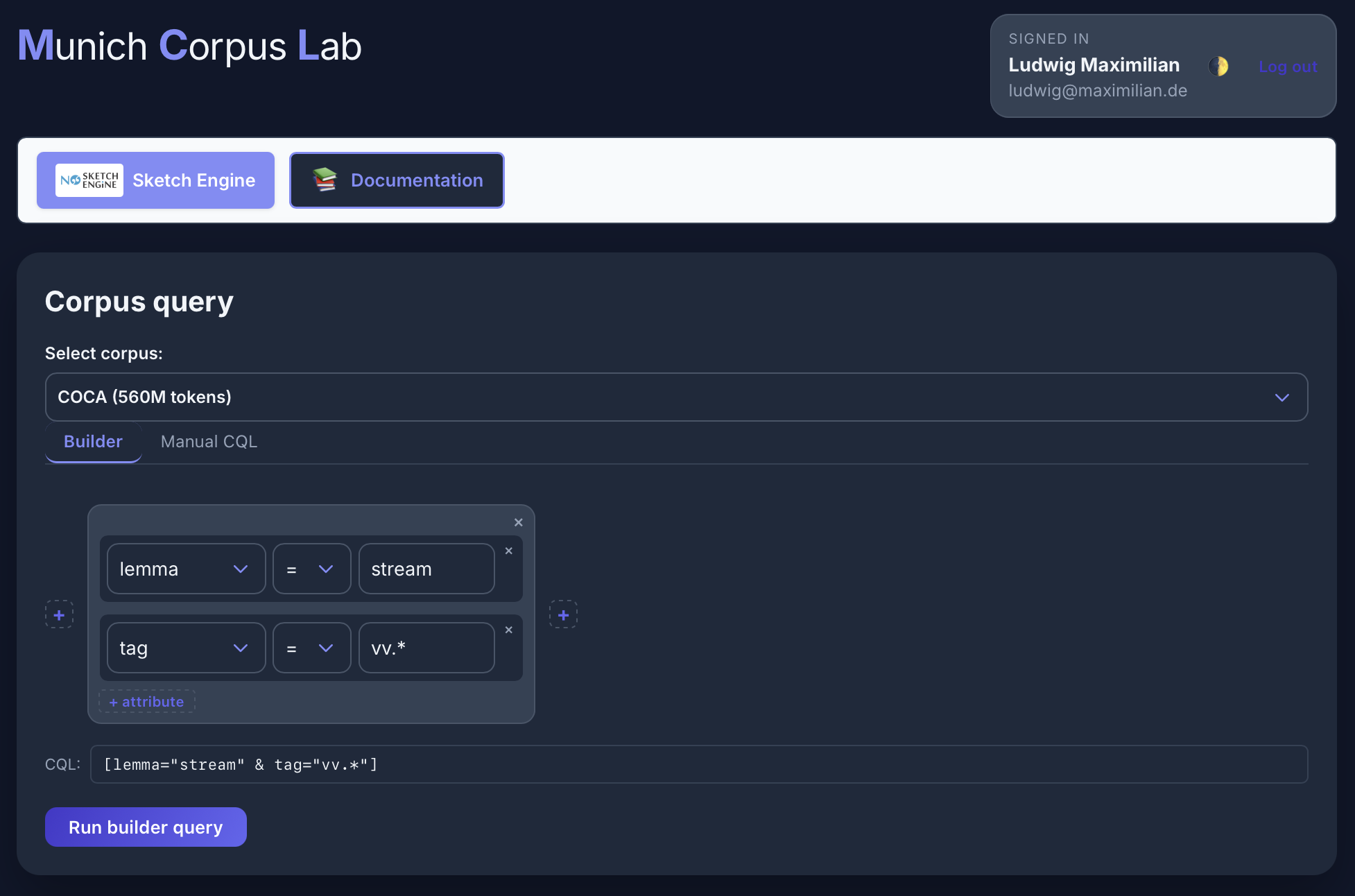
No Sketch Engine interface
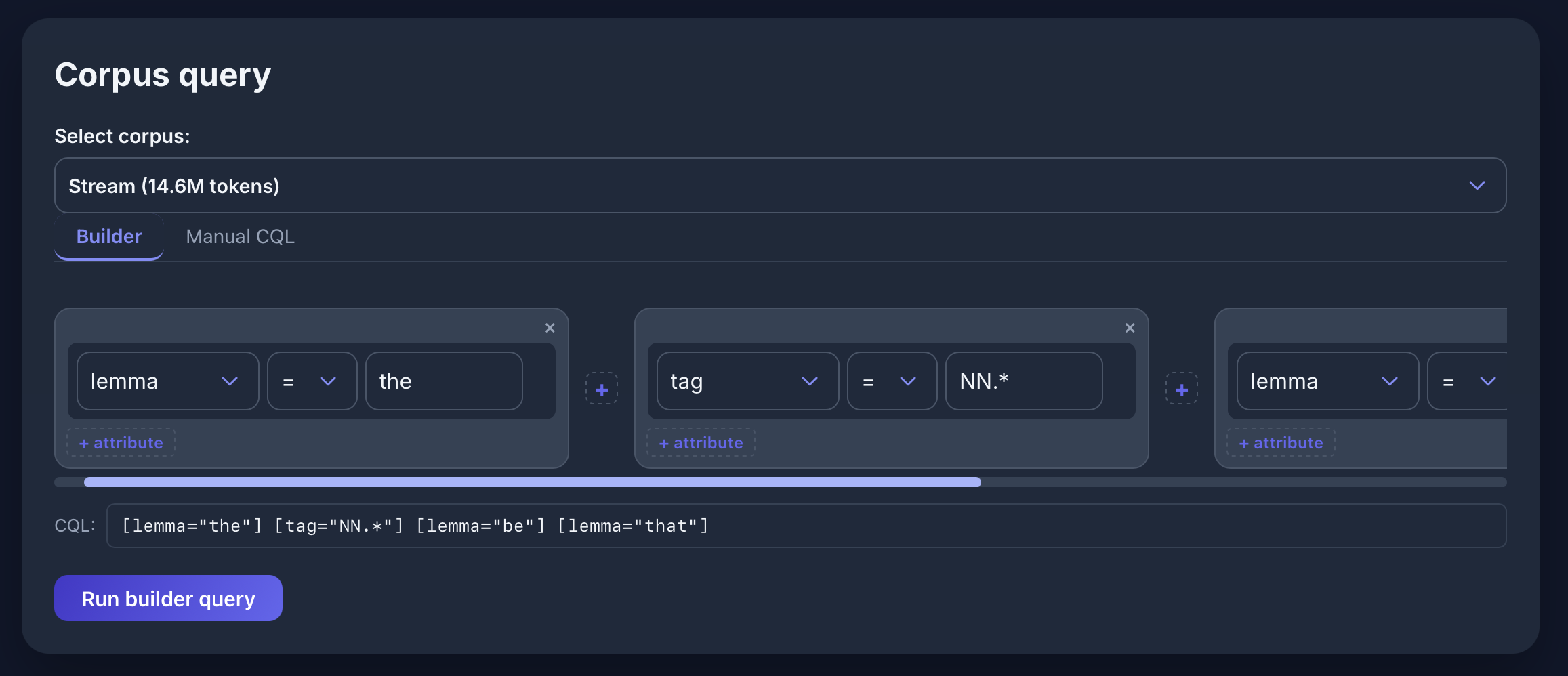
Query Builder

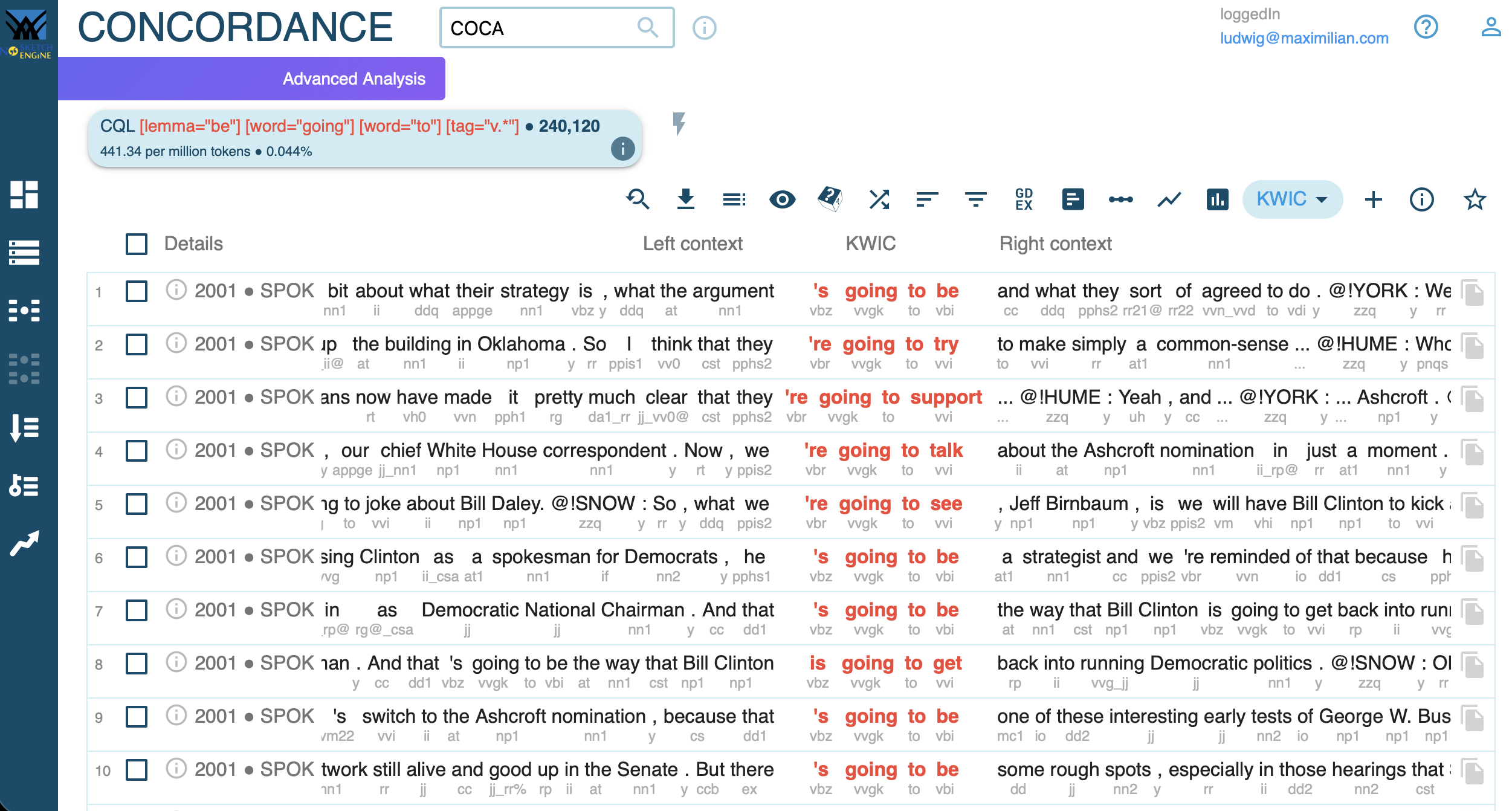
Concordance View
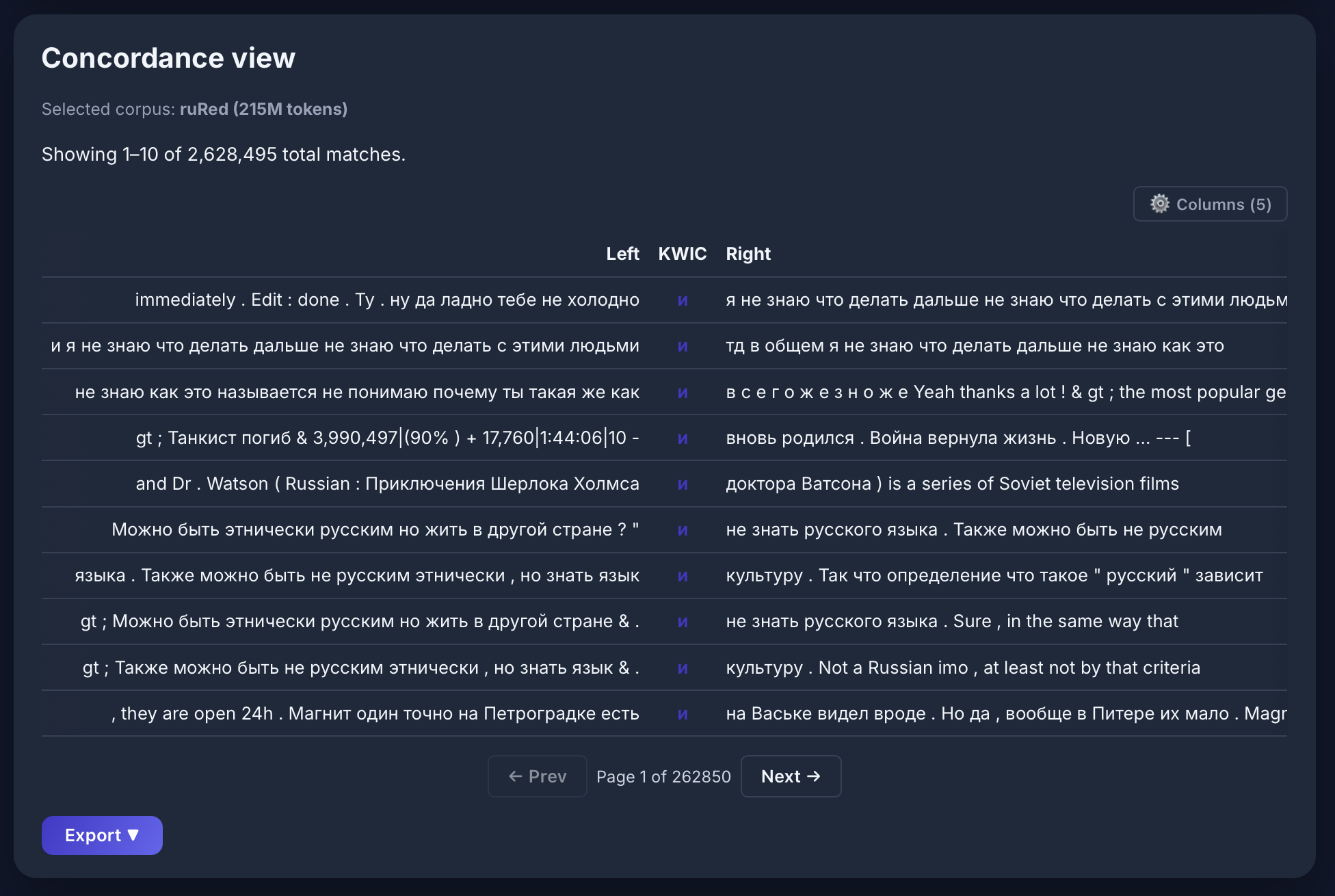
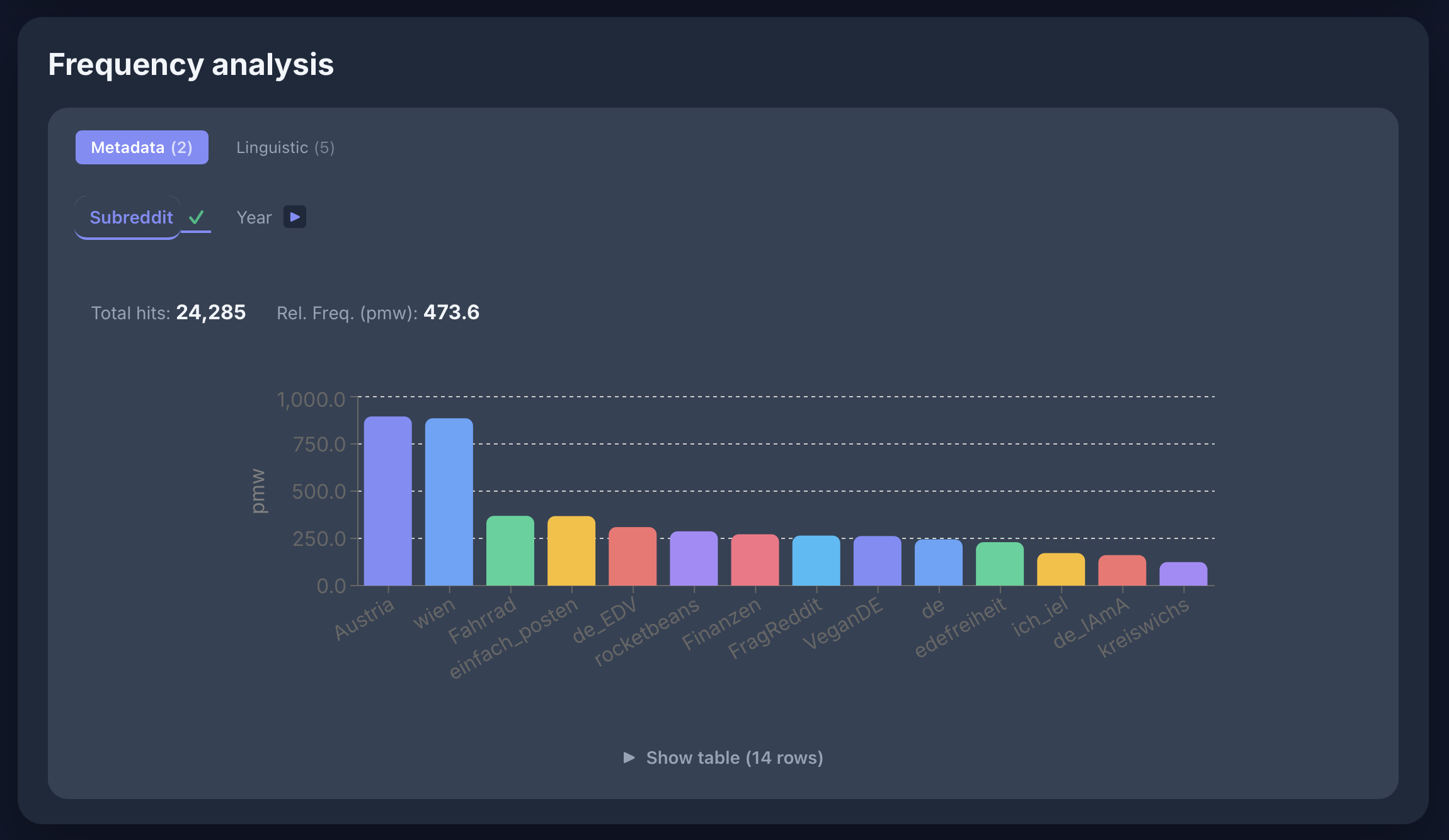
Slowakisch: Polysemie von strana
[lemma="strana"] im skRed-Korpus — 57.717 Treffer:
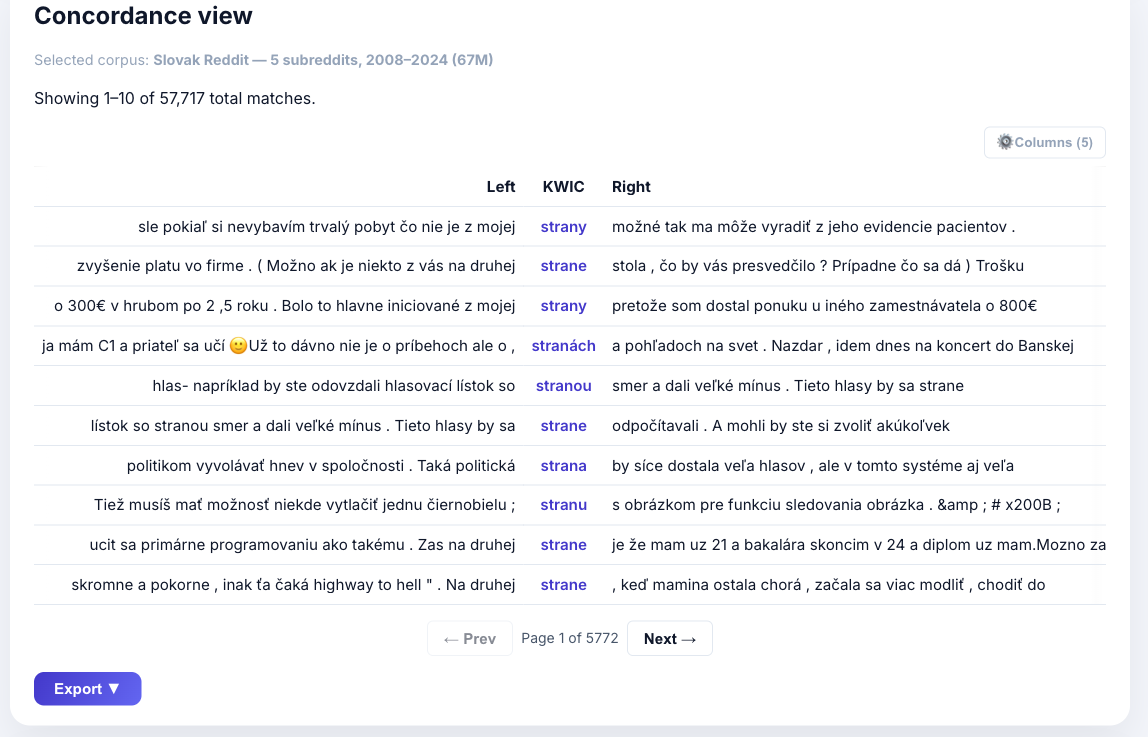
Frequenzanalyse
Verb in [lemma="be"] [word="going"] [word="to"] [tag="VB.*"] im Stream-Korpus:
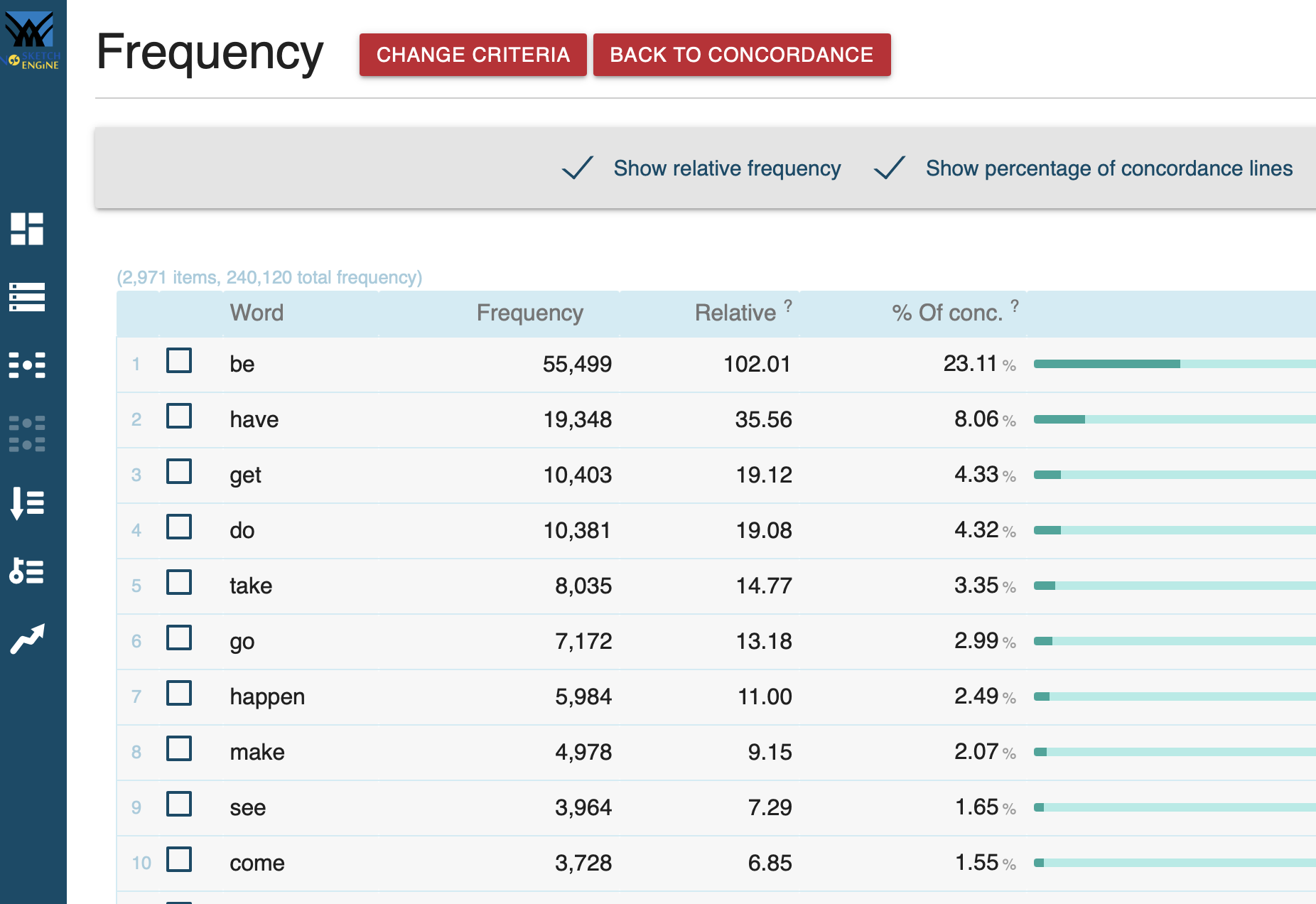
Wort-Formen für [lemma="denken"] im GeRedE-Korpus:
Frequenz von [word="eh"] zwischen Communities im GeRedE-Korpus:
[lemma="virus"] im Russian Reddit - Korpus:
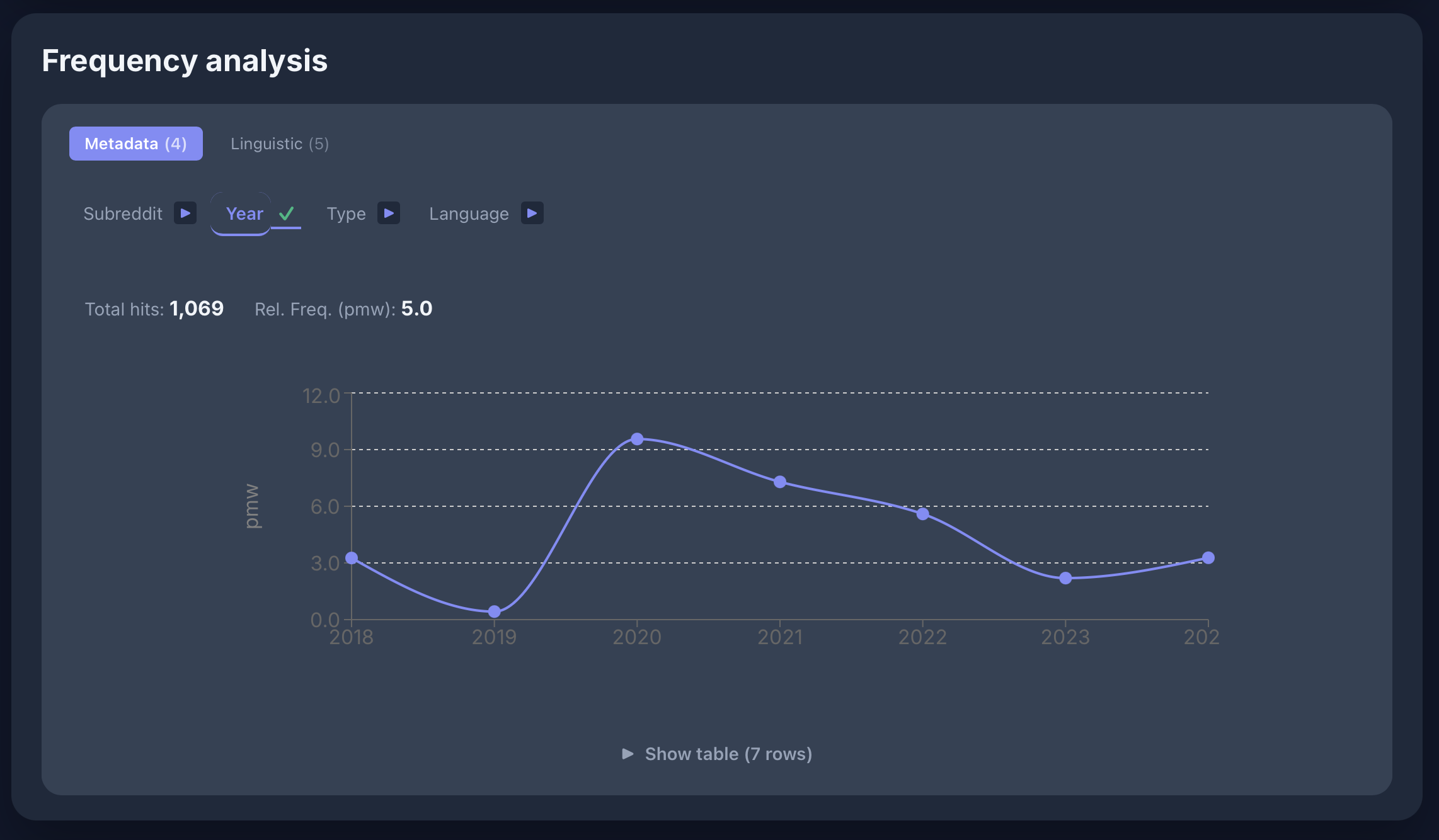
Slowakisch: Diachrone Entwicklung
[lemma="strana"] im skRed-Korpus — Frequenz nach Jahr:
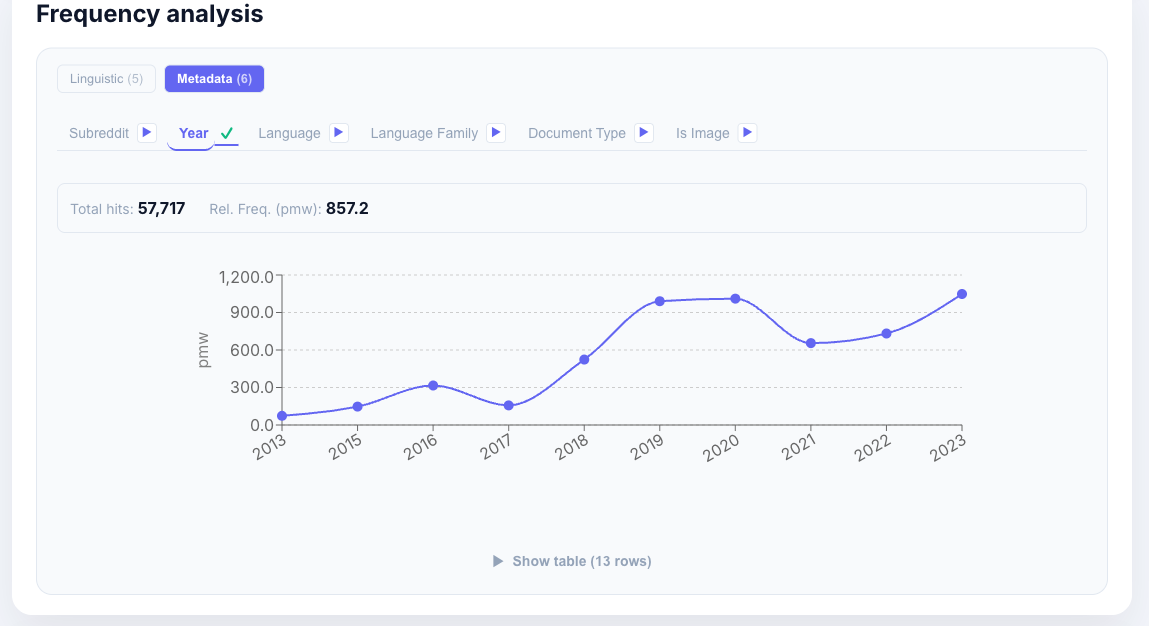
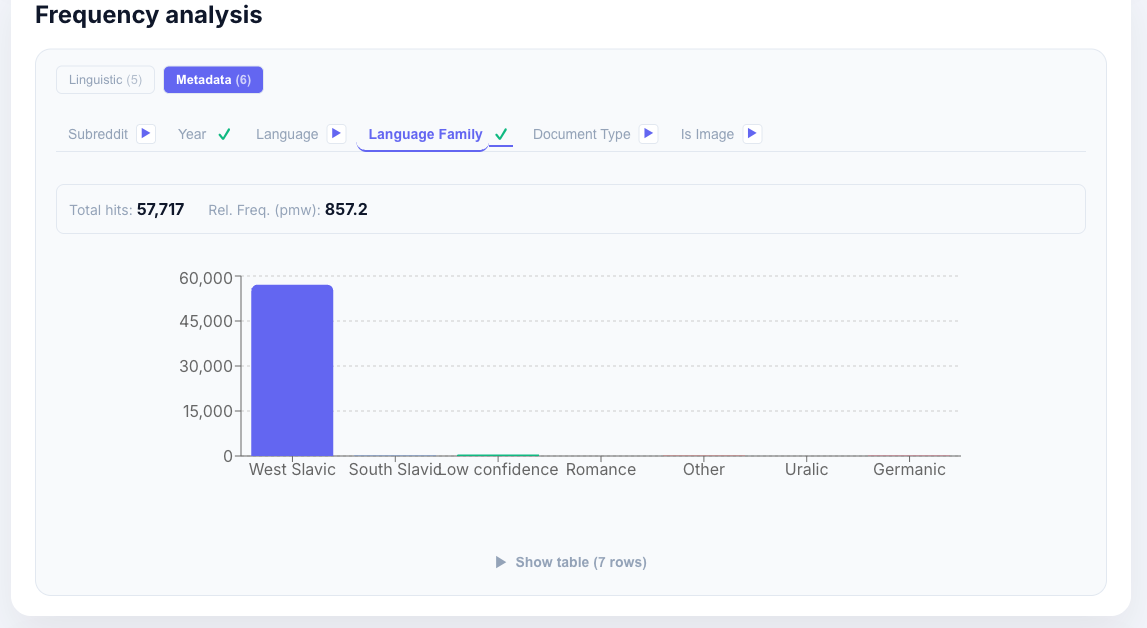
Slowakisch: Sprachfamilienverteilung
[lemma="strana"] im skRed-Korpus — Frequenz nach Sprachfamilie:
Dependenzen
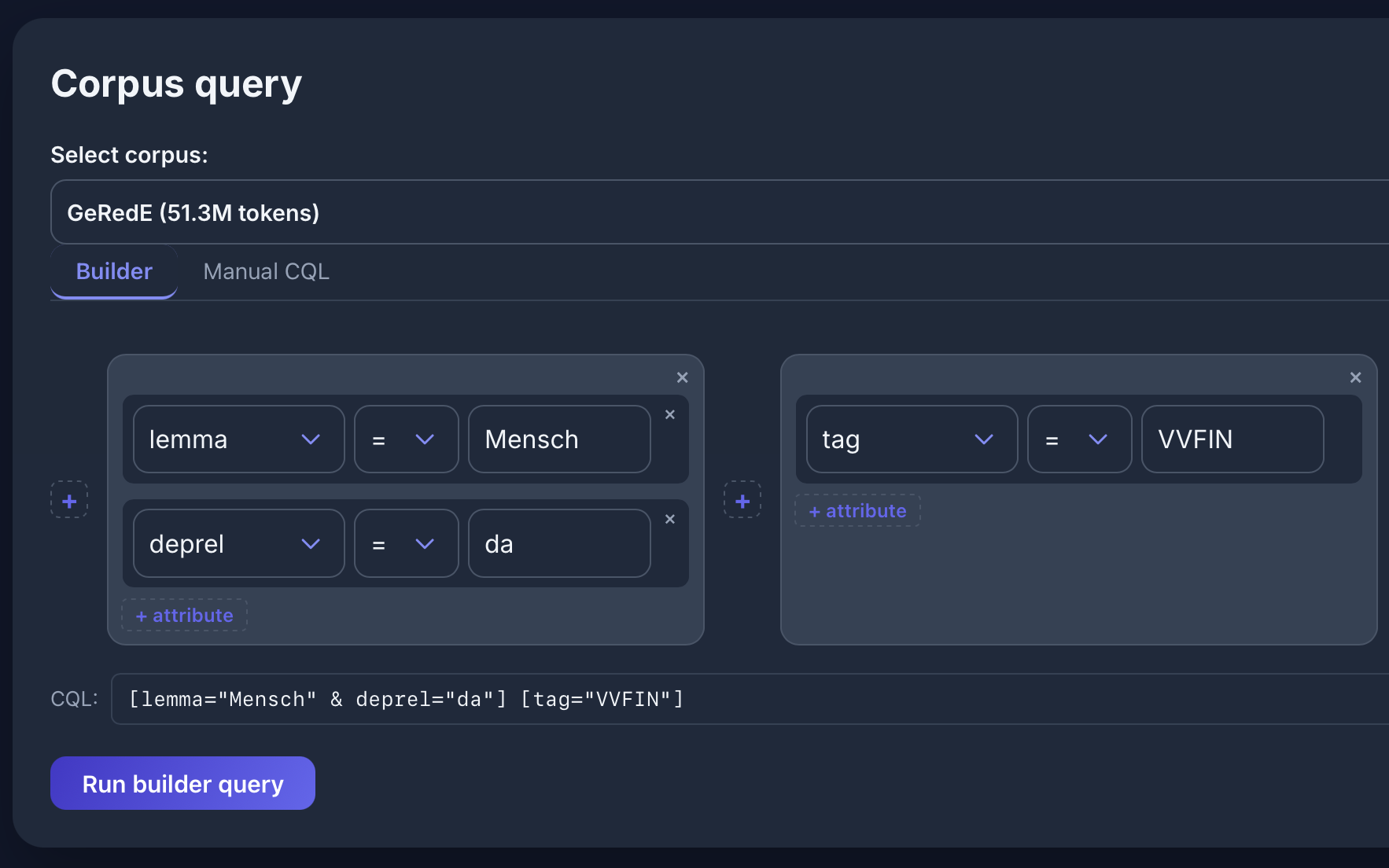
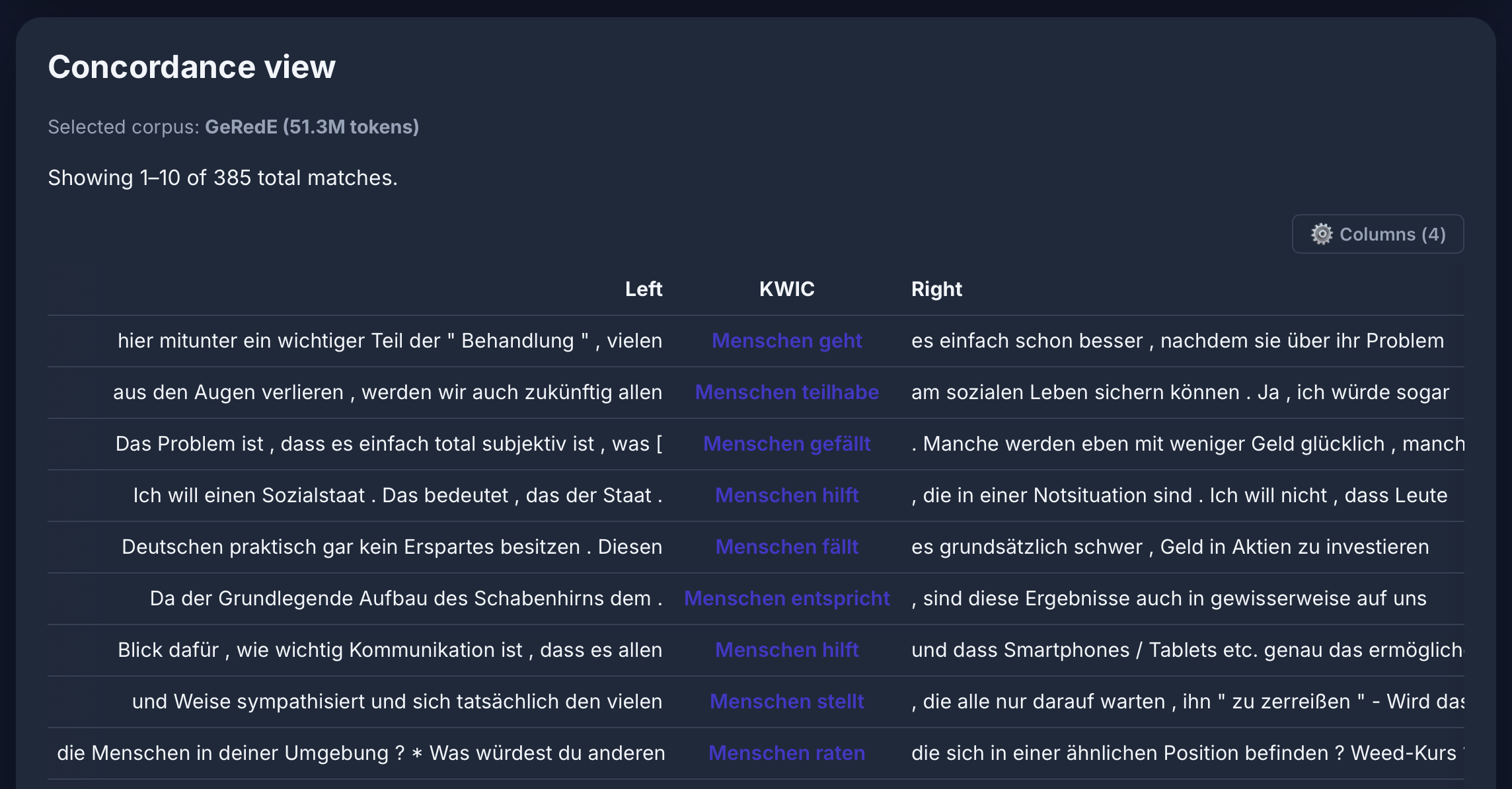
[lemma="Mensch" & deprel="da"] [tag="VVFIN"] im GeRedE-Korpus:
Slowakisch: Reflexivmarker “sa” — Grammatikalisierung
[lemma="sa"] — Dependency-Verteilung:
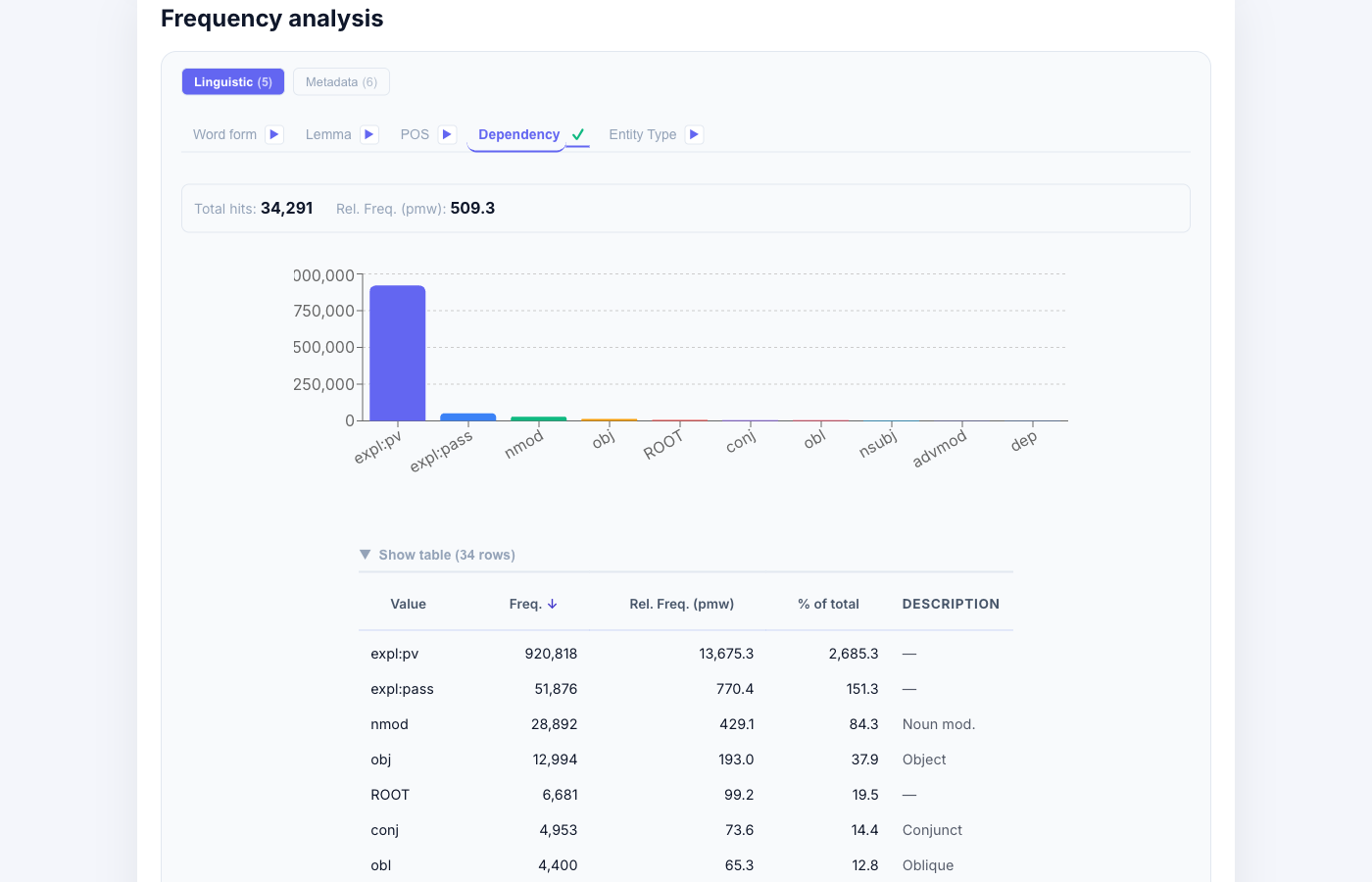
~90% nicht als inhärent reflexiv klassifiziert.
| Tag | Bedeutung | Beispiel |
|---|---|---|
expl:pv |
Inhärent reflexiv | vyjadriť sa (sich äußern) |
expl:pass |
Reflexivpassiv | sa riešilo (wurde besprochen) |
obj |
Echtes Reflexiv | myjem sa (ich wasche mich) |
Named Entities
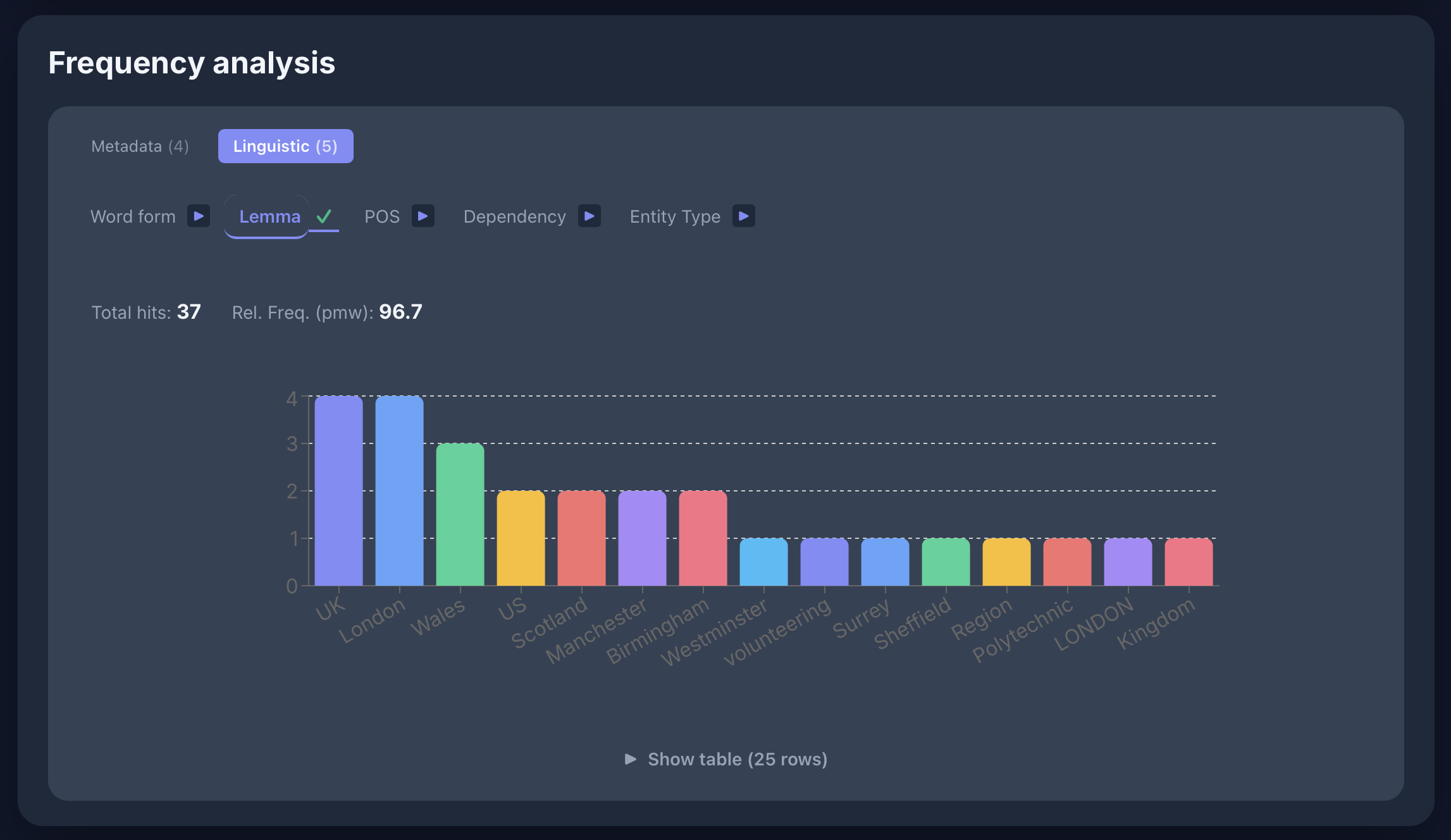
[ent_type="GPE" & deprel="dobj"] im UniPlans-Korpus:
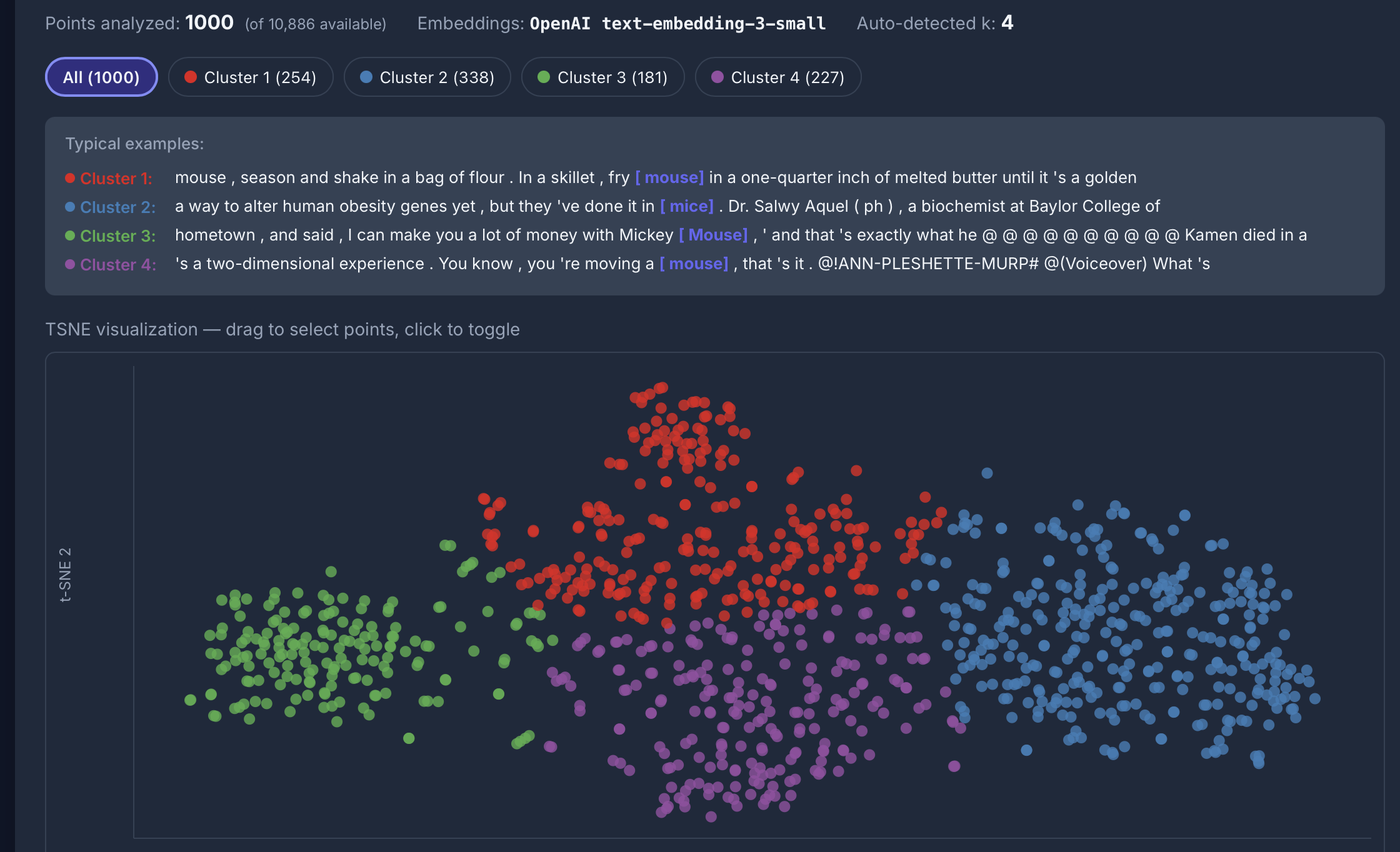
Semantic analysis
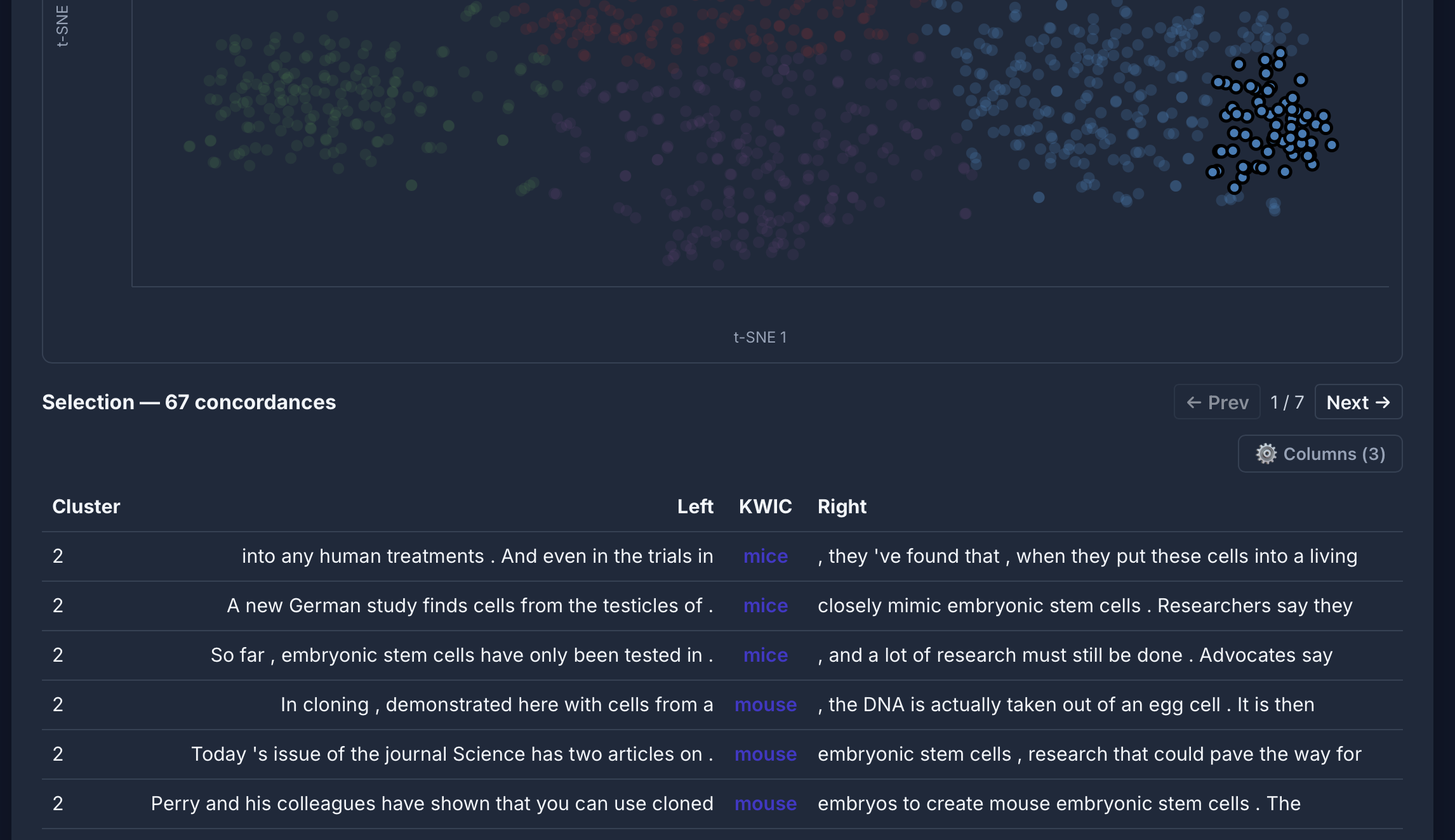
[lemma="mouse"] im COCA:
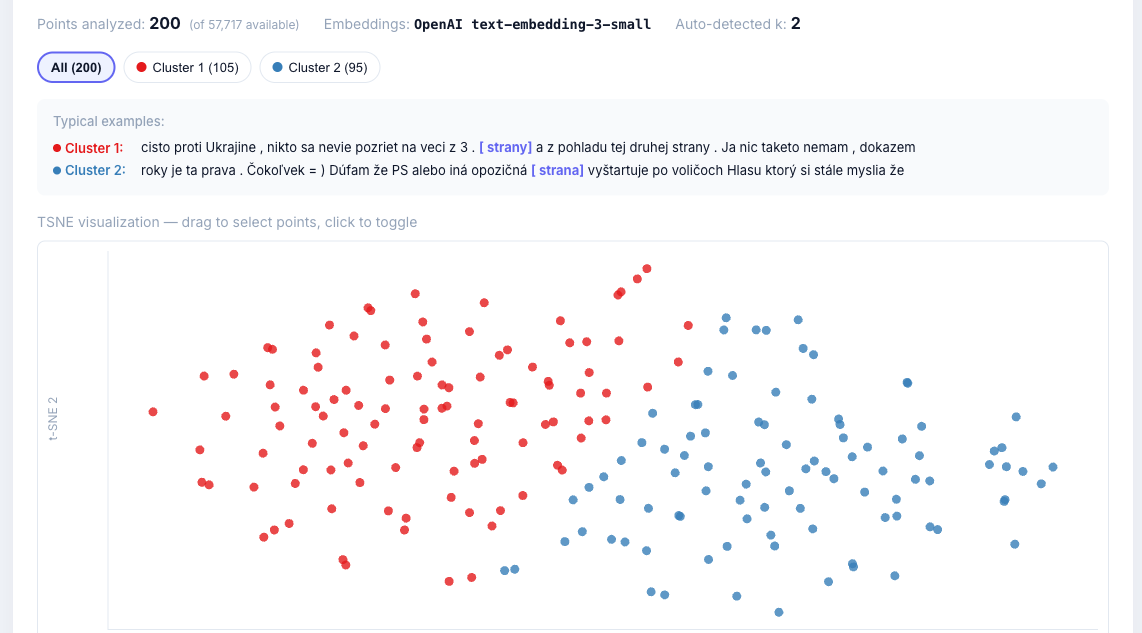
Slowakisch: Polysemie-Cluster
[lemma="strana"] — t-SNE Clustering (200 Samples, Silhouette: 0.409):
LLM classification
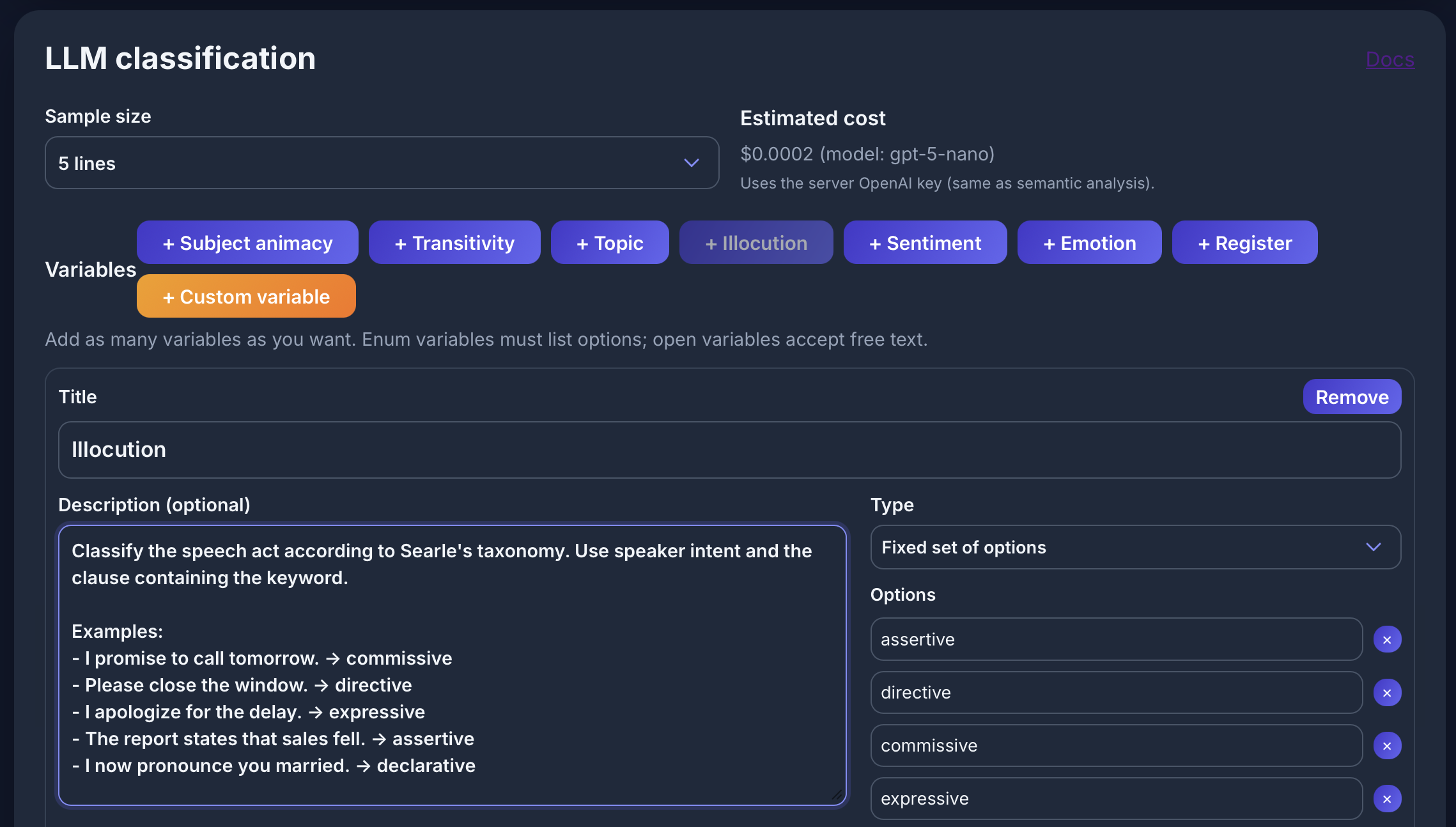
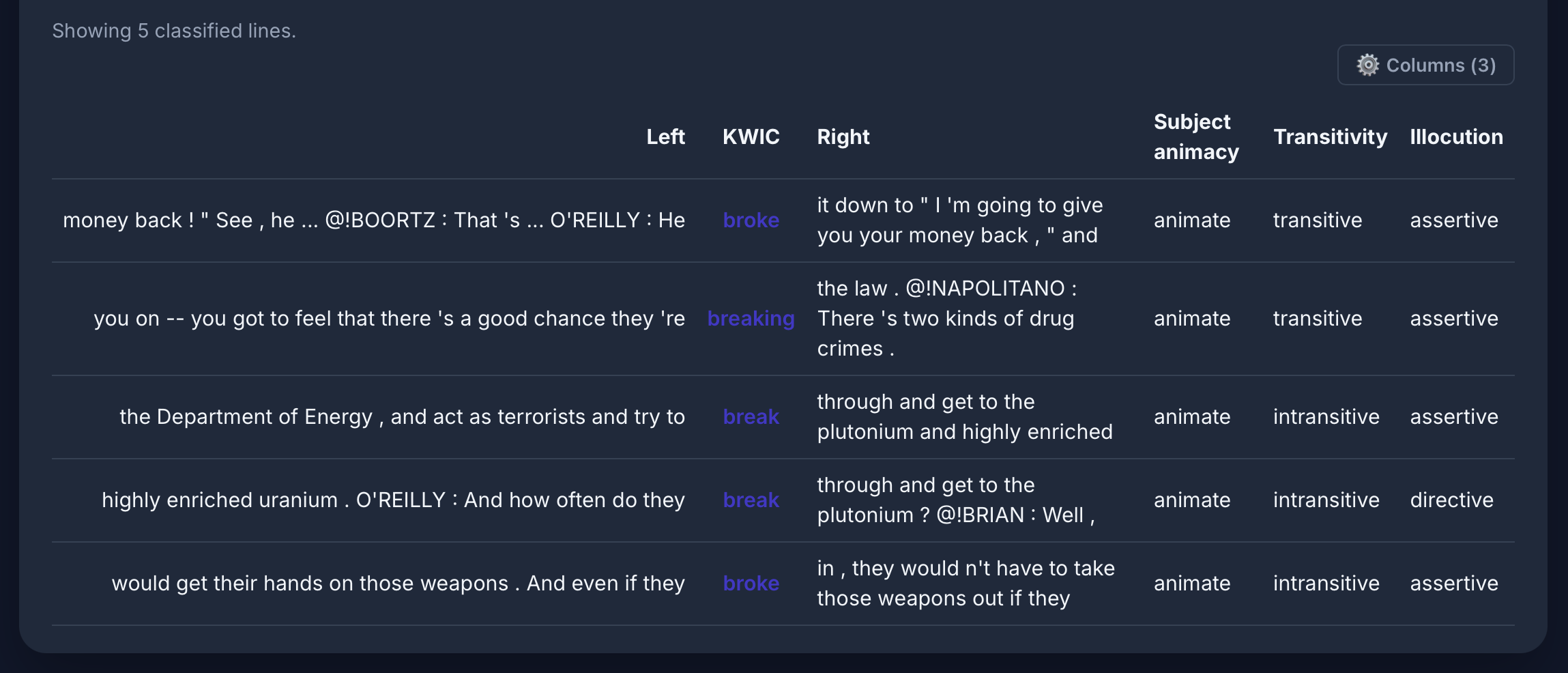
Causative alternation für [lemma="break" & tag="vv.*"] im COCA:
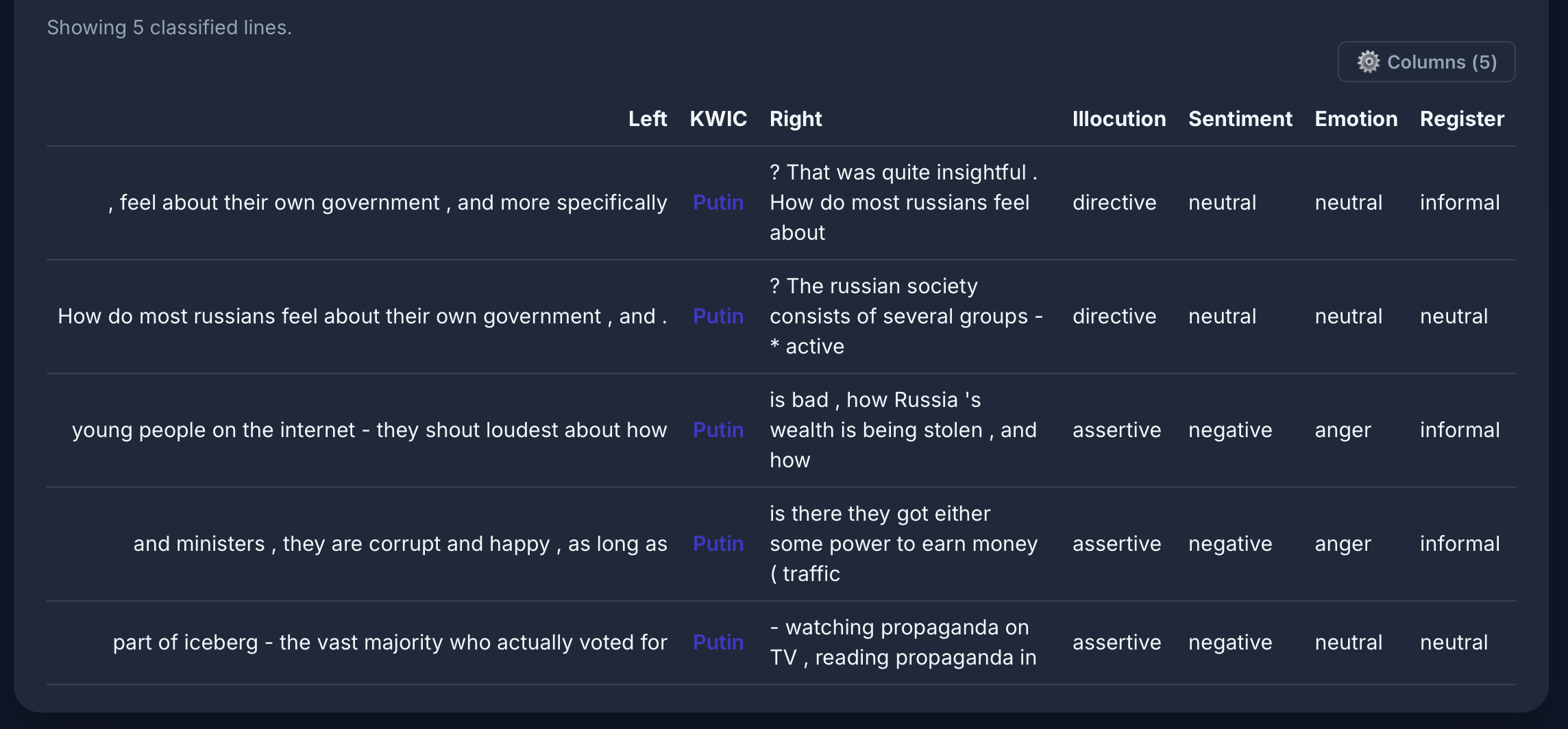
[word="Putin"] im Russian Reddit-Korpus:
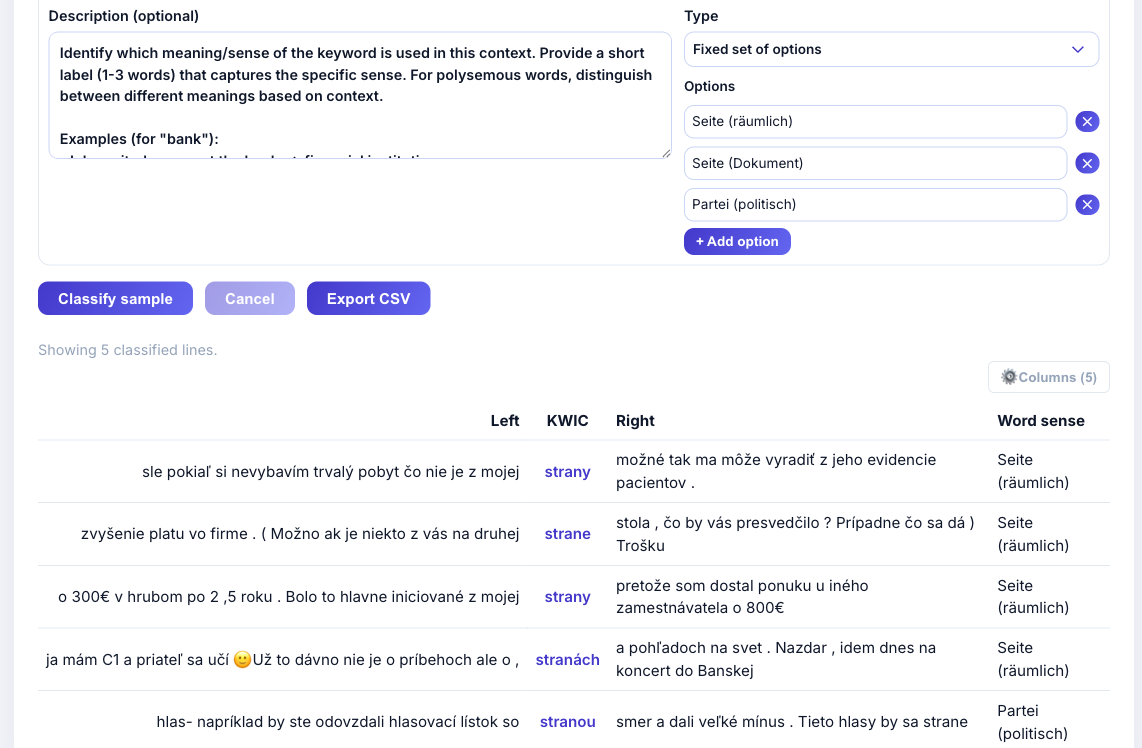
Slowakisch: Word Sense Disambiguation
[lemma="strana"] — Polysemie-Klassifikation:
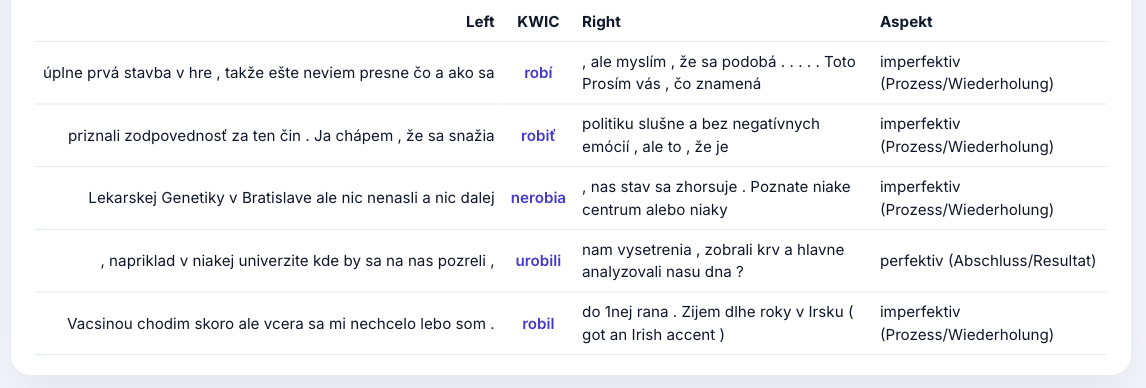
Slowakisch: Aspekt-Klassifikation
[lemma="robiť" | lemma="urobiť"] — perfektiv vs. imperfektiv:
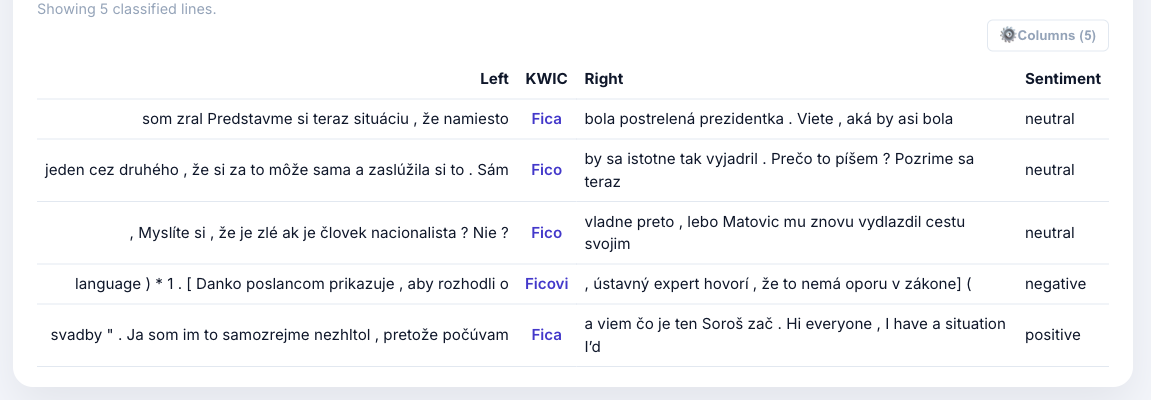
Slowakisch: Sentiment-Analyse
[word="Fico" | word="Ficovi" | word="Fica"] — Einstellung zum slowakischen PM:
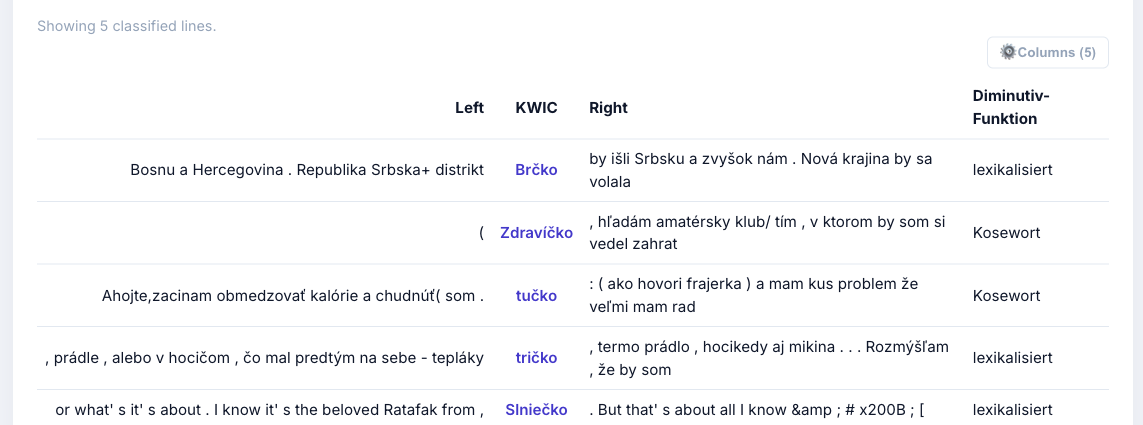
Slowakisch: Diminutiv-Funktion
[word=".*[íč]ko"] — Funktion der Diminutivformen:
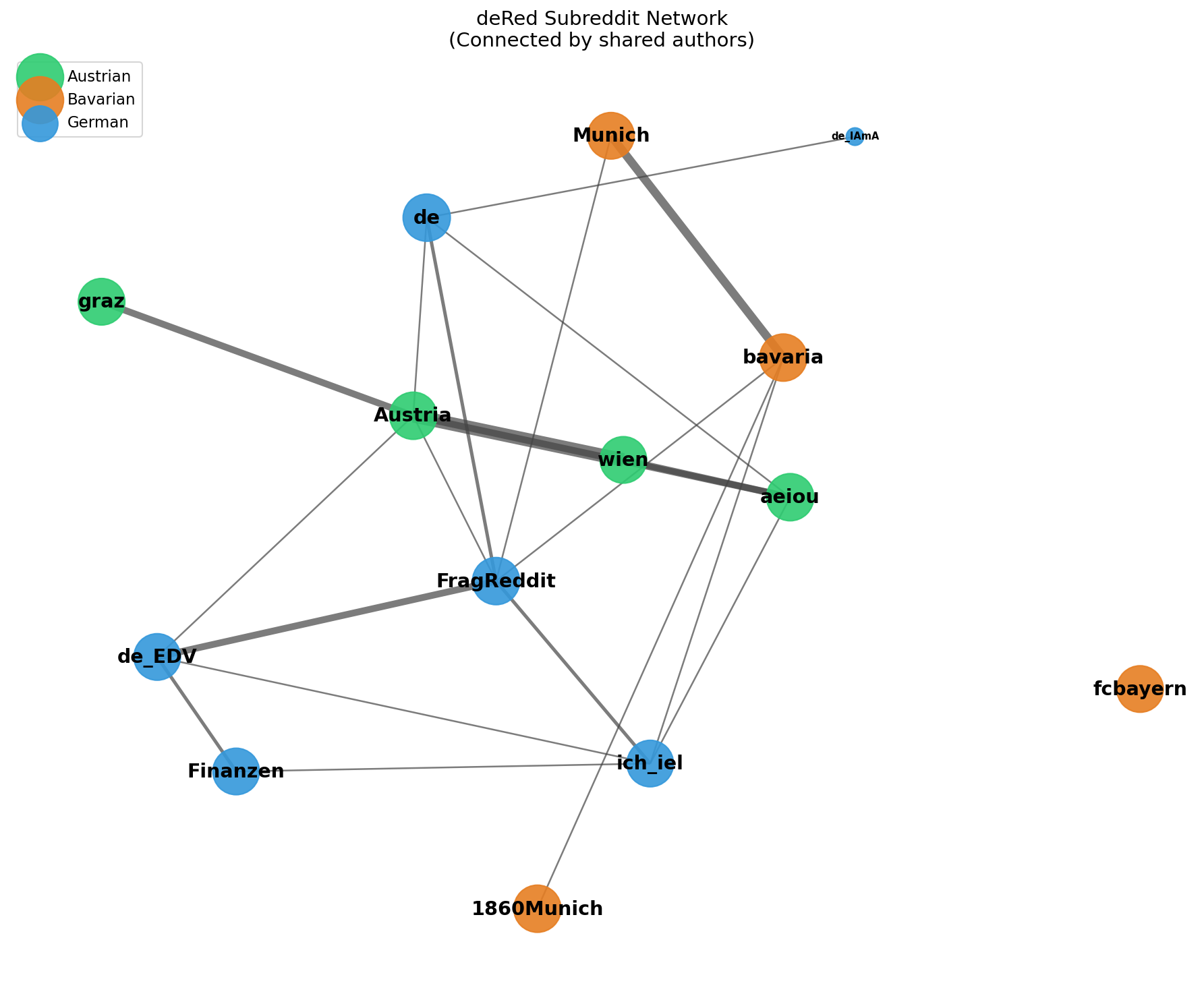
Subreddit-Netzwerk
User Interaction Network (r/Austria)
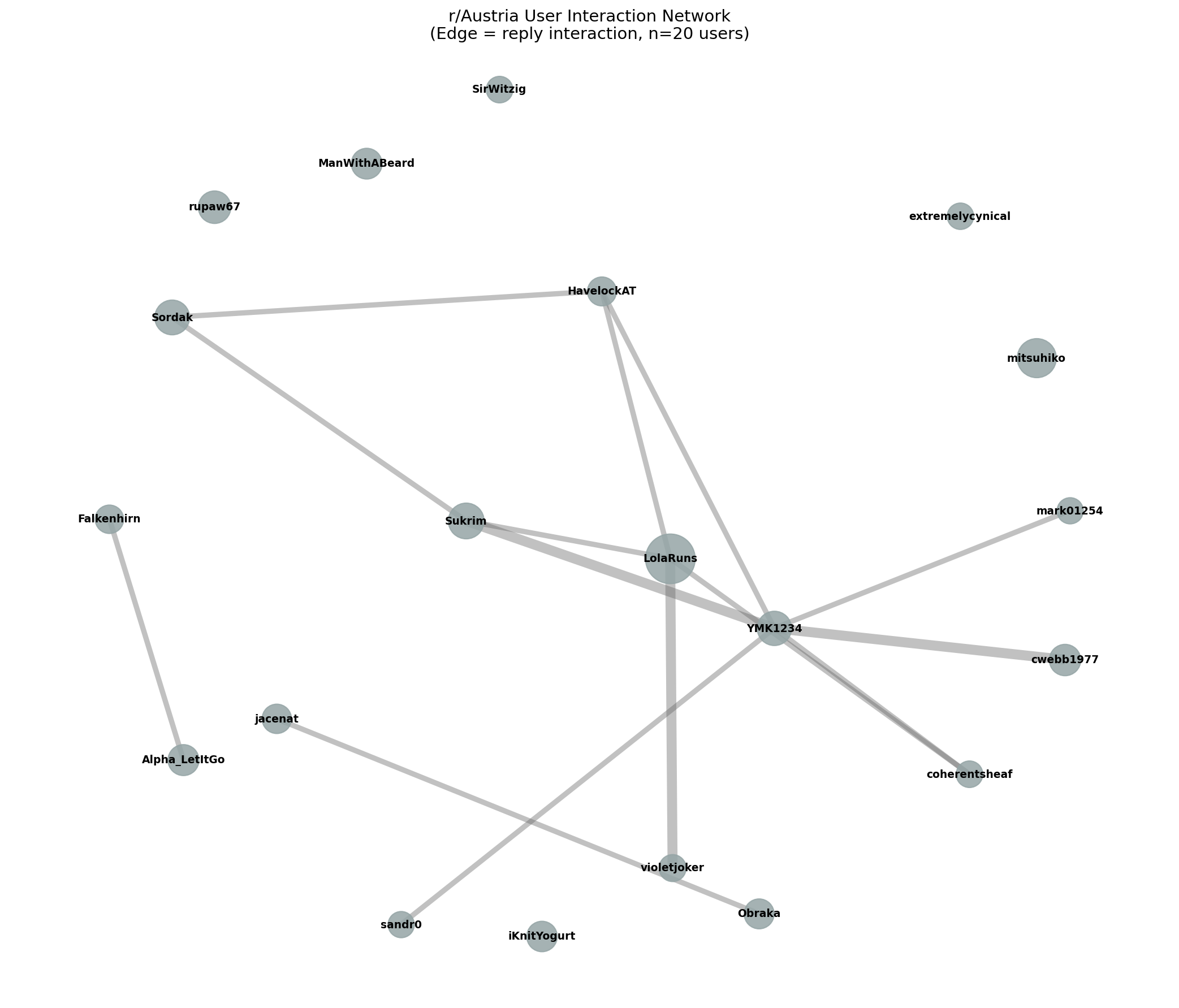
Social Network Analysis