Munich Corpus Lab
Germanistische Linguistik, LMU München

Die Munich Corpus Lab App
https://www.wuerschinger.org/mcl
Benutzername: lipp@lmu.de
Passwort: Sch3ll!ng1860
React interface
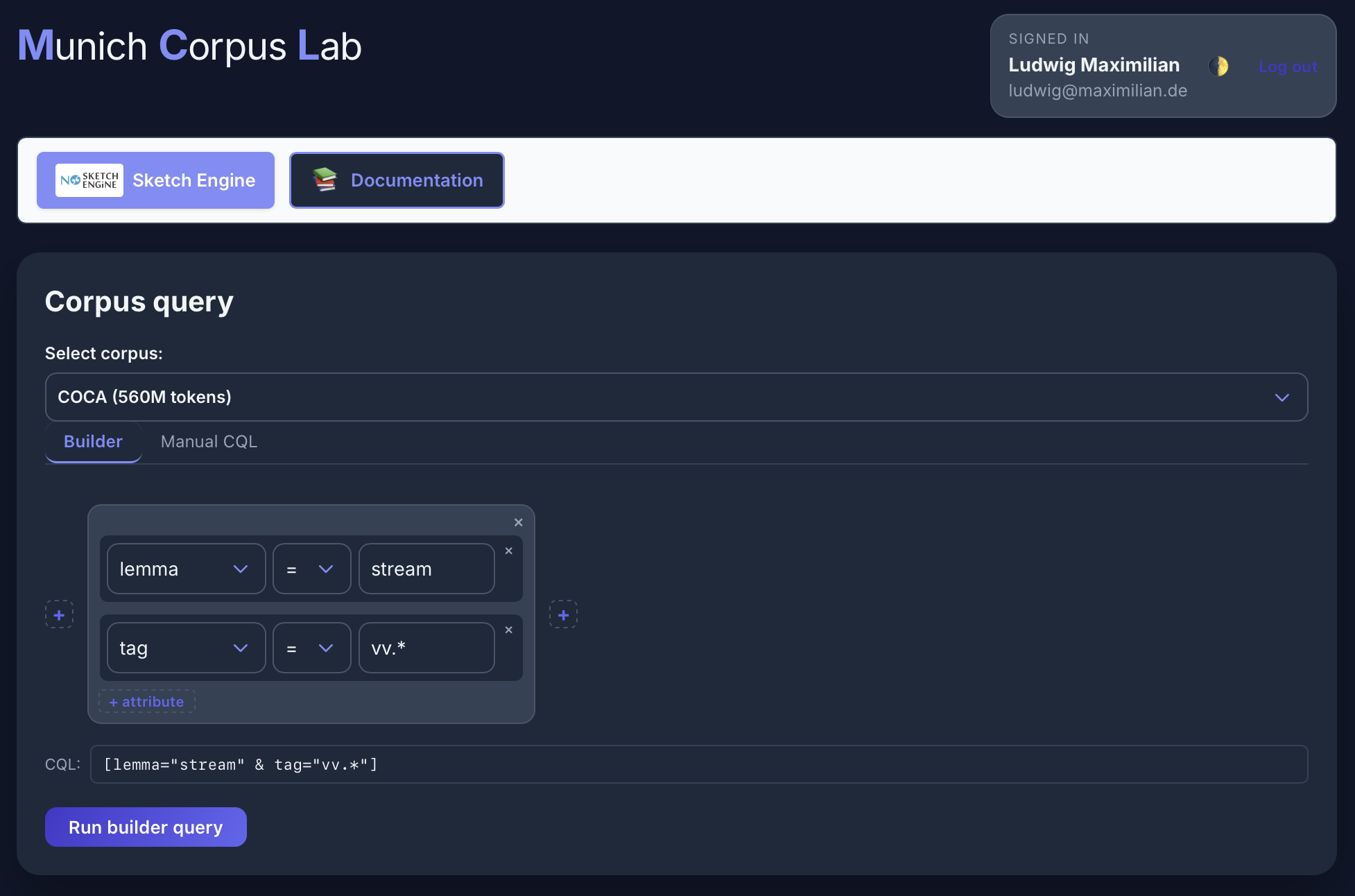
No Sketch Engine interface
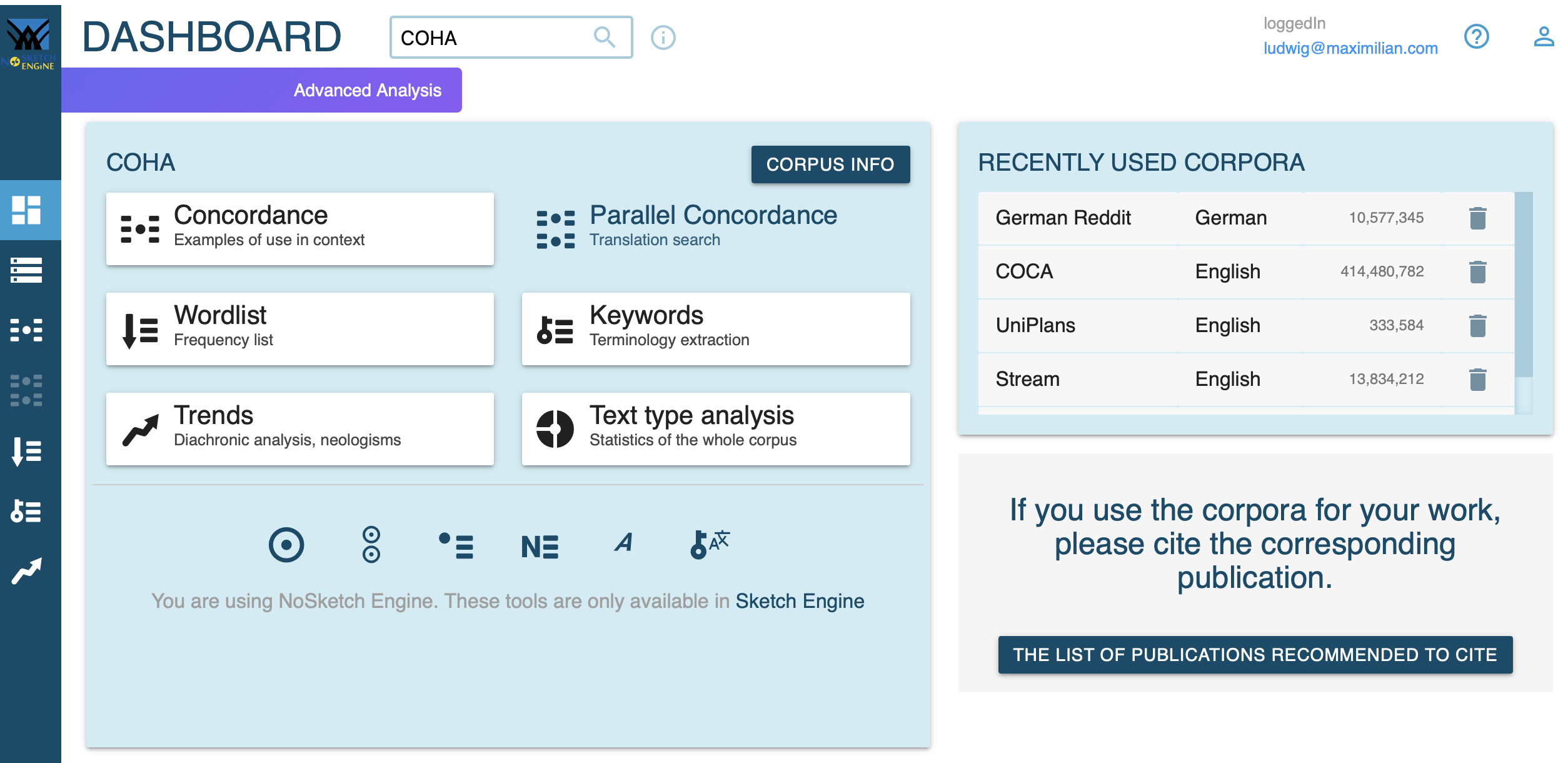
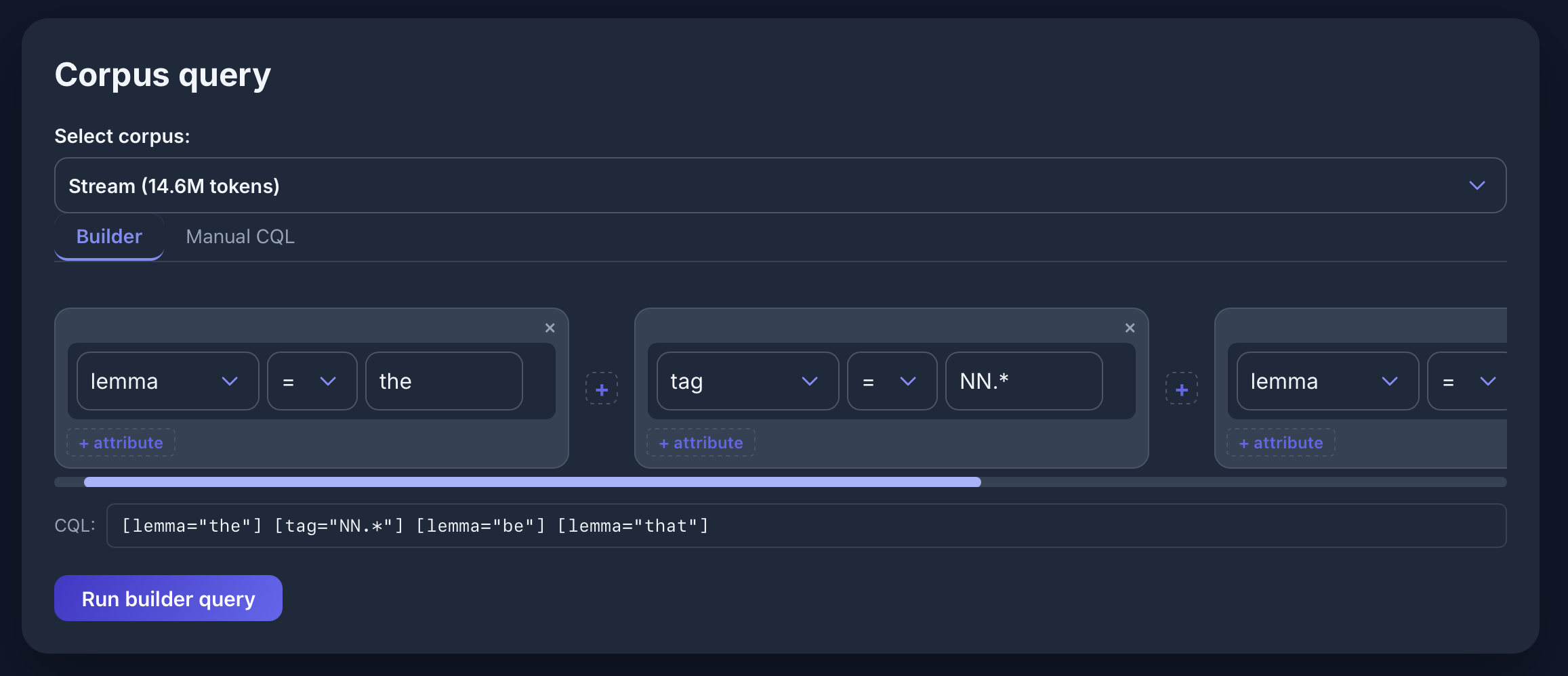
Query Builder

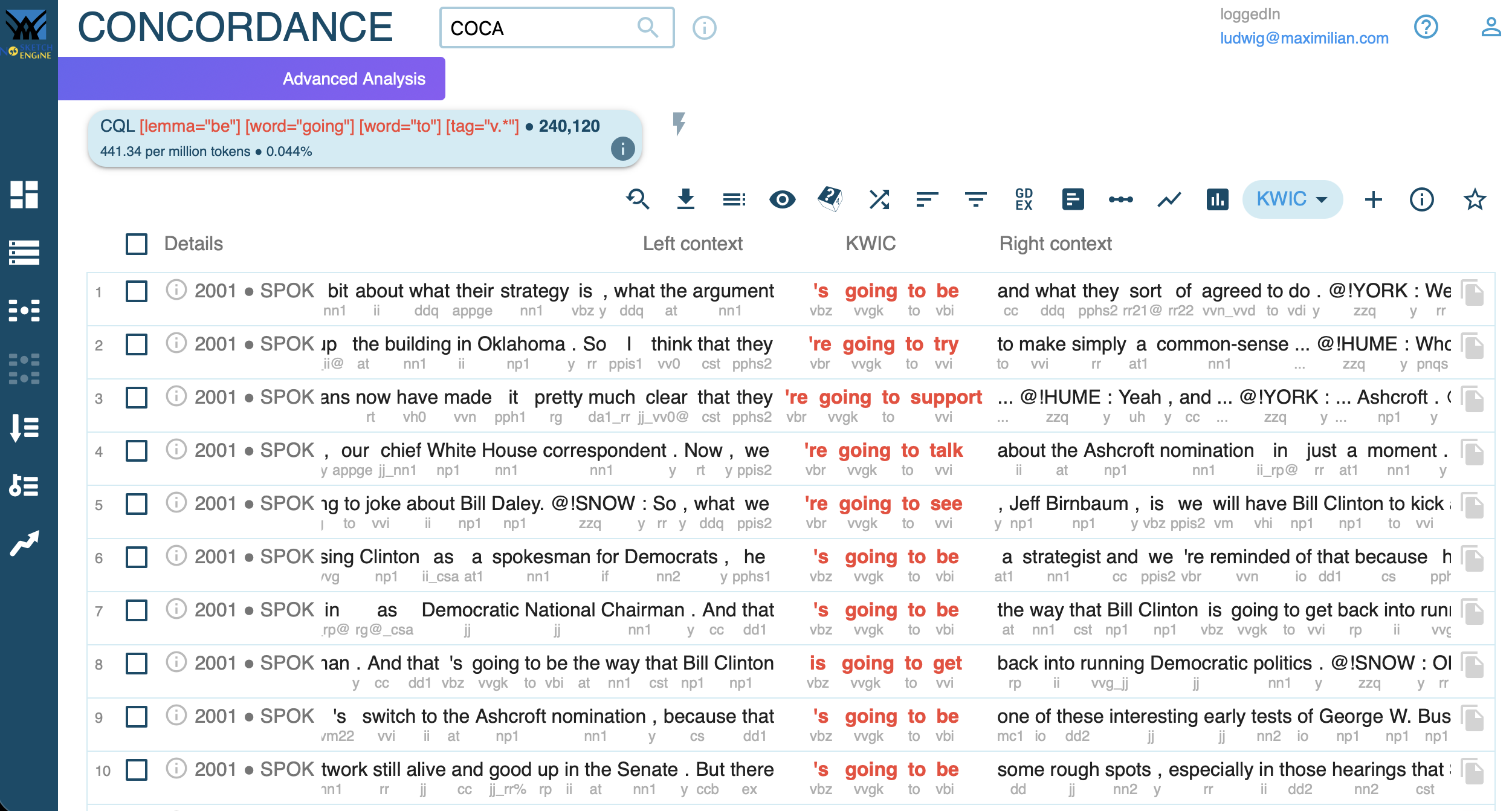
Concordance View
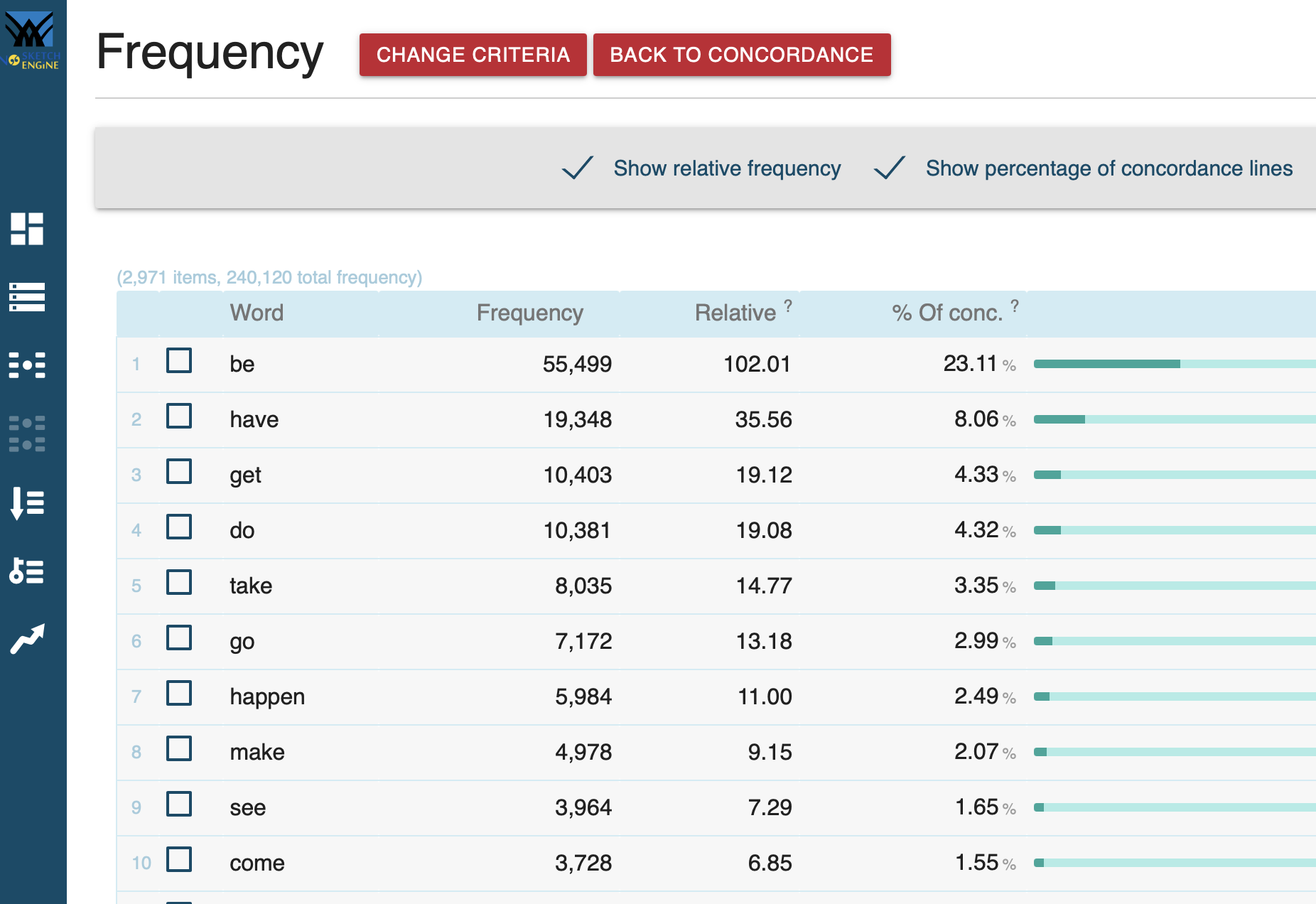
Frequenzanalyse
Verb in [lemma="be"] [word="going"] [word="to"] [tag="VB.*"] im Stream-Korpus:
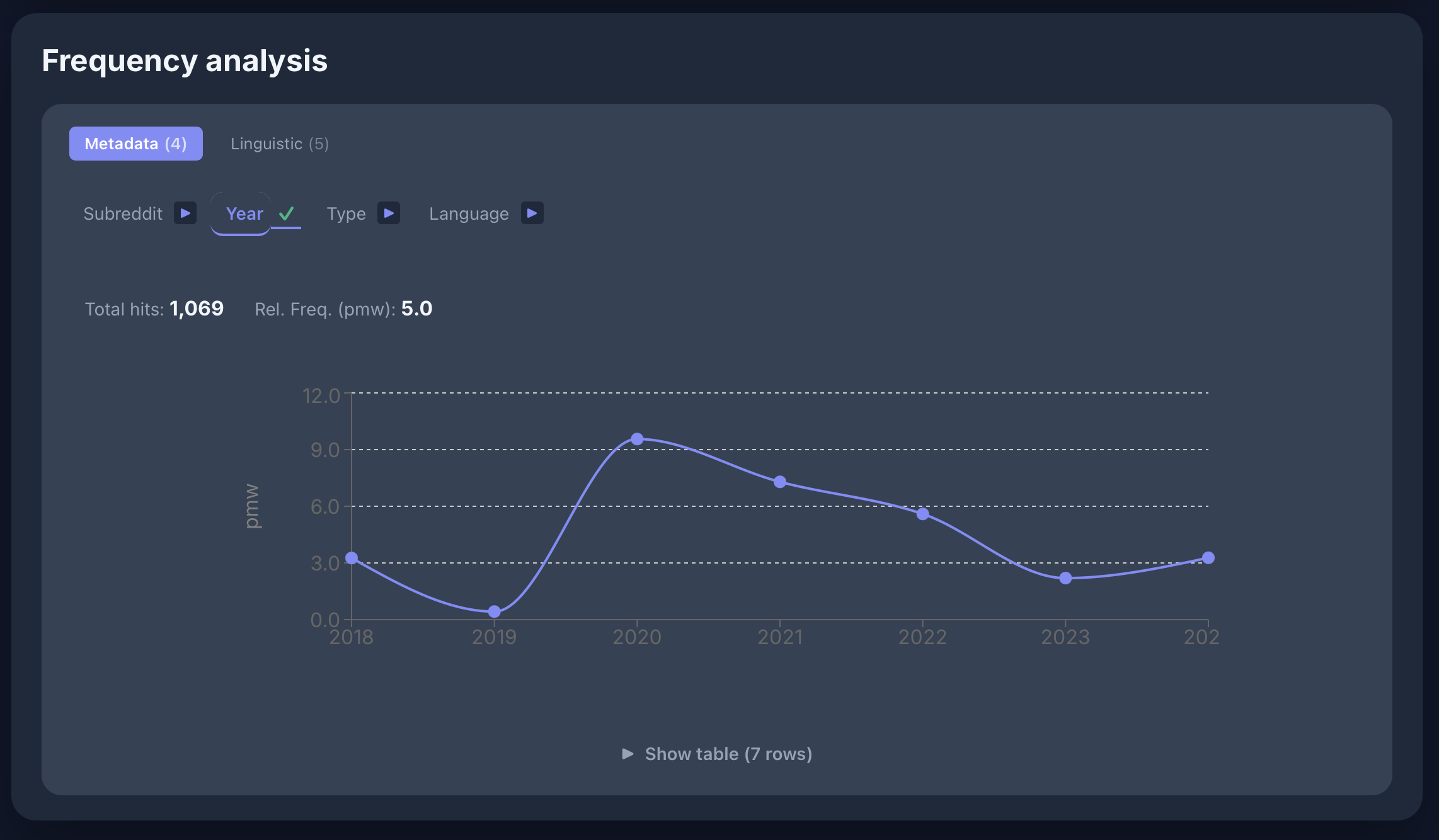
[lemma="virus"] im Russian Reddit - Korpus:
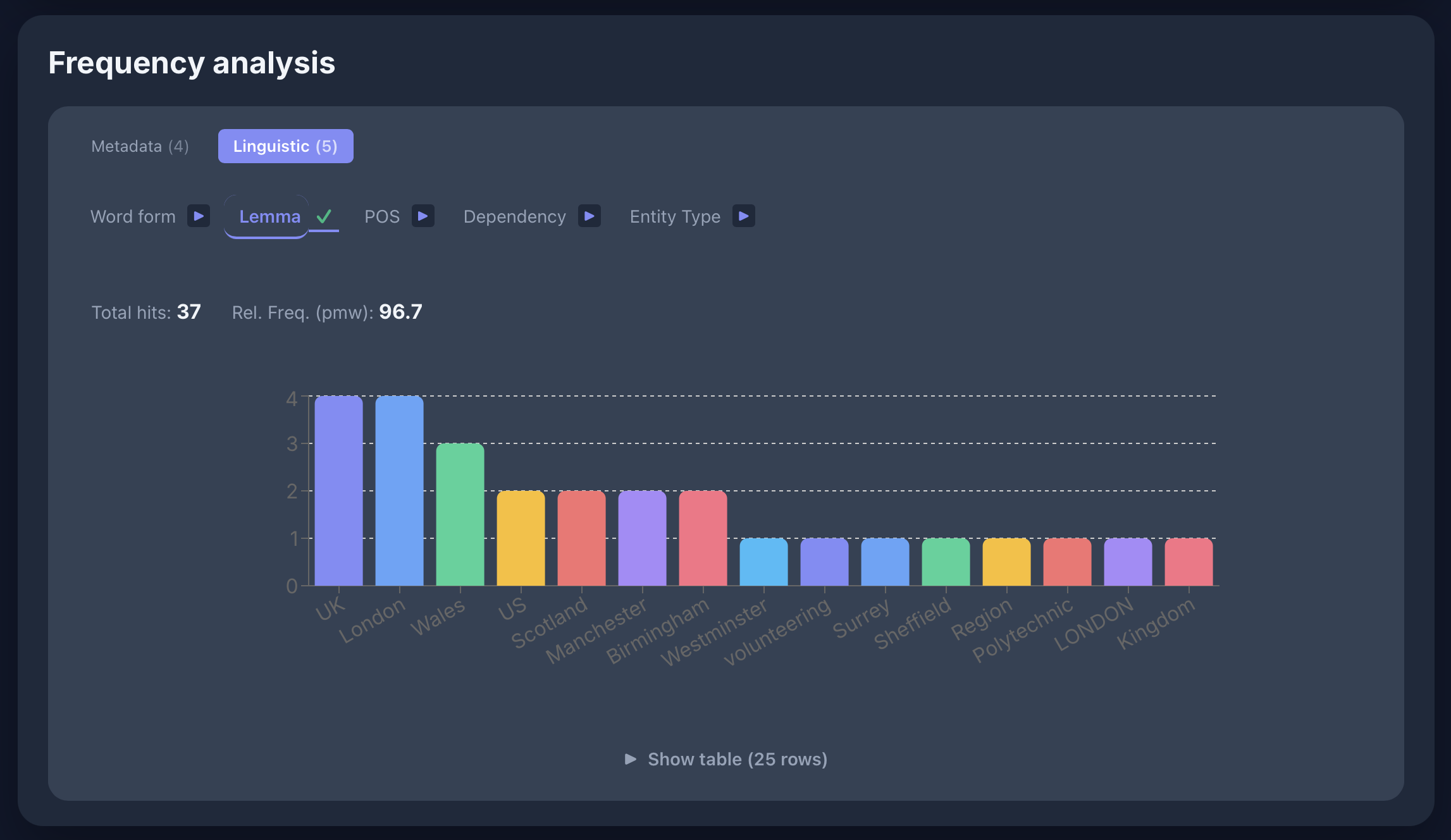
Named Entities
[ent_type="GPE" & deprel="dobj"] im UniPlans-Korpus:
Semantic analysis
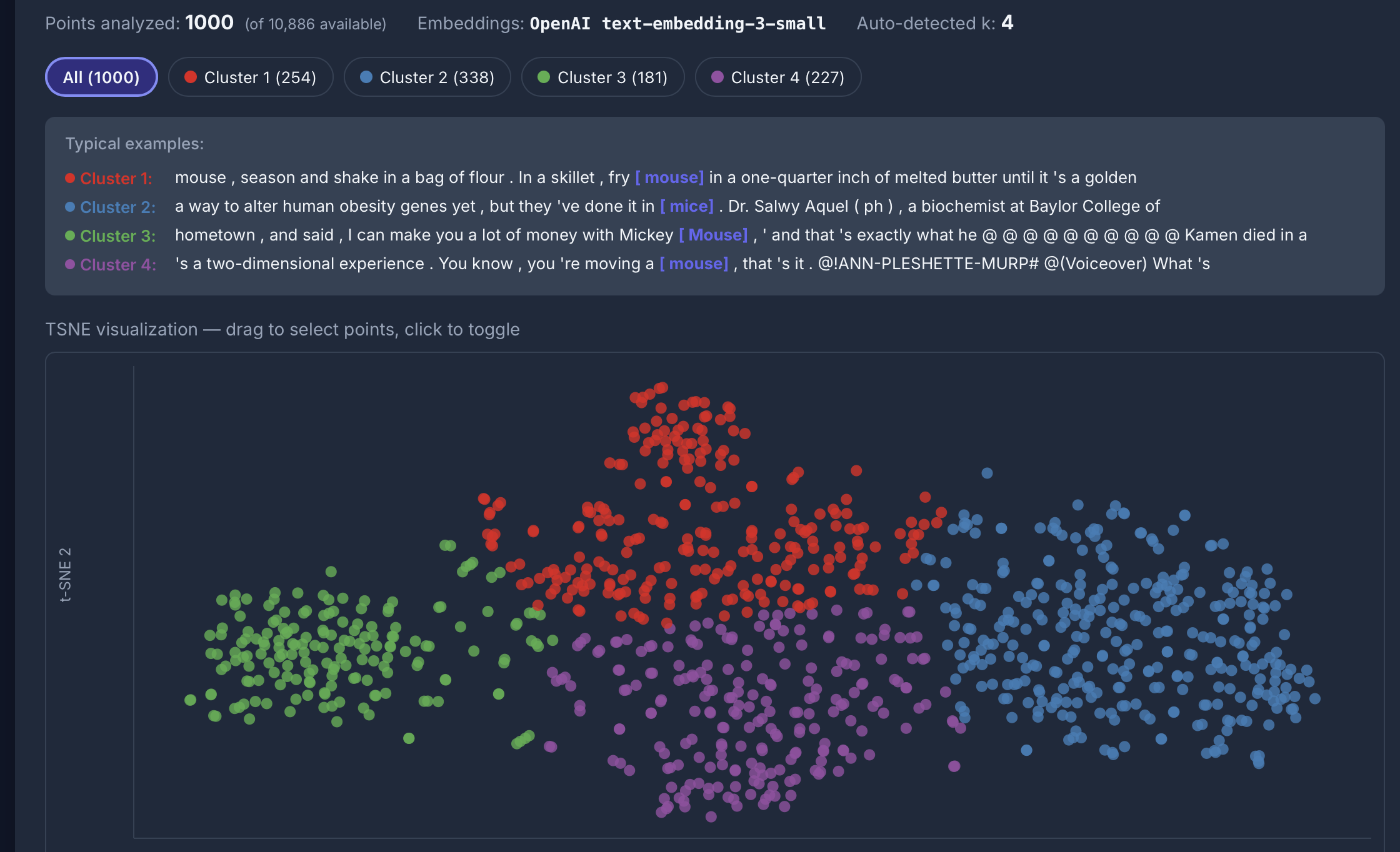
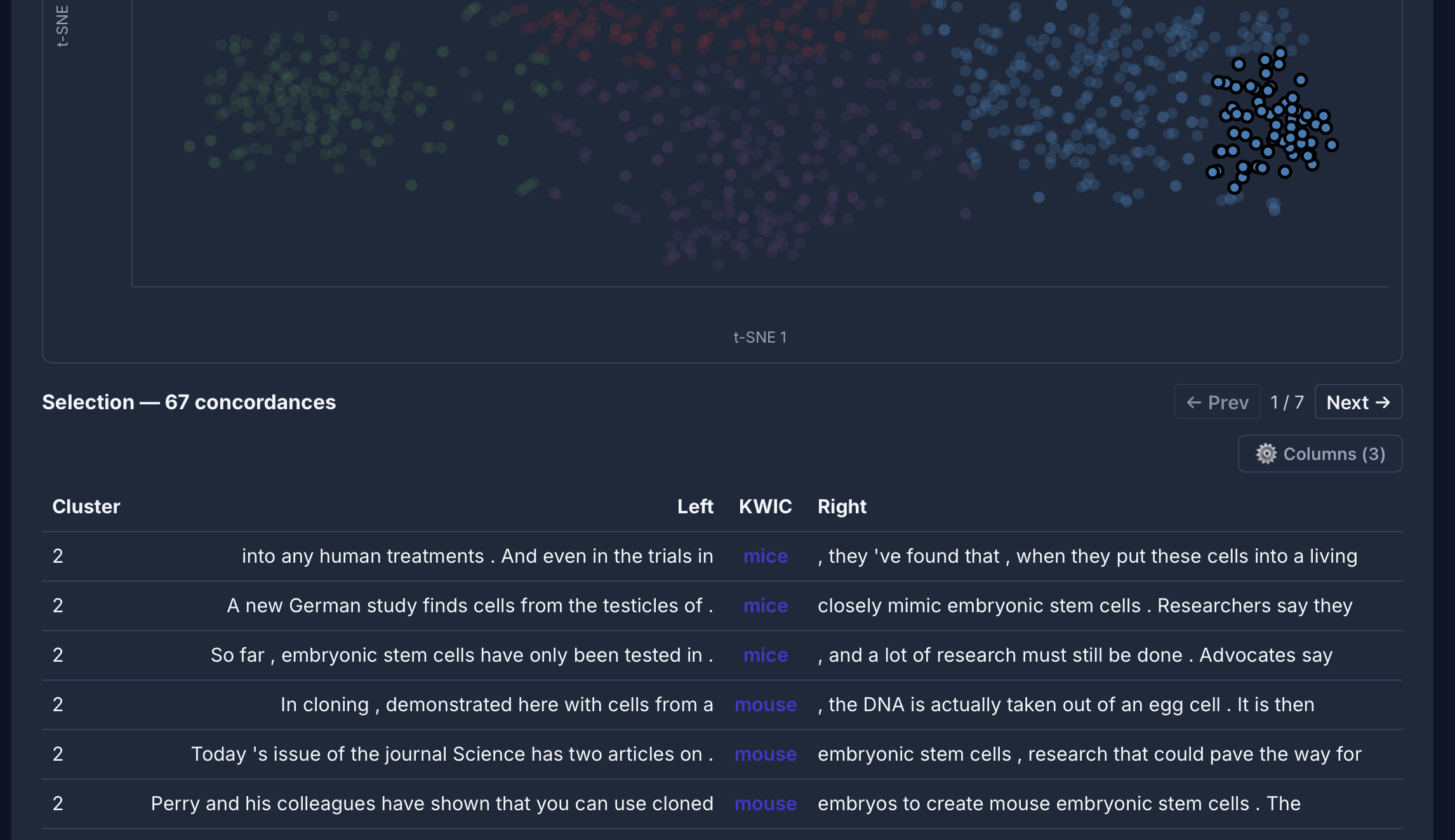
[lemma="mouse"] im COCA:
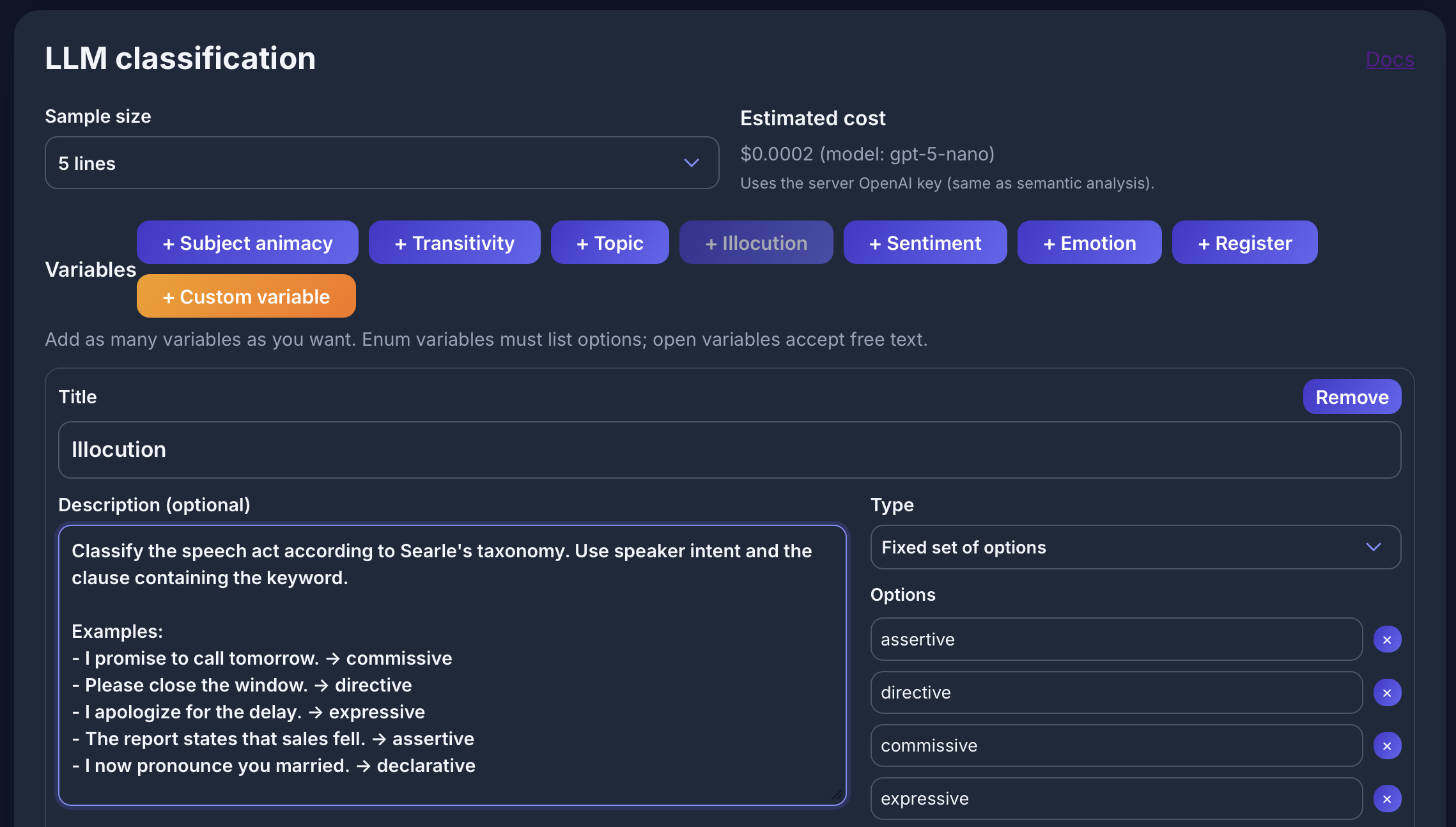
LLM classification
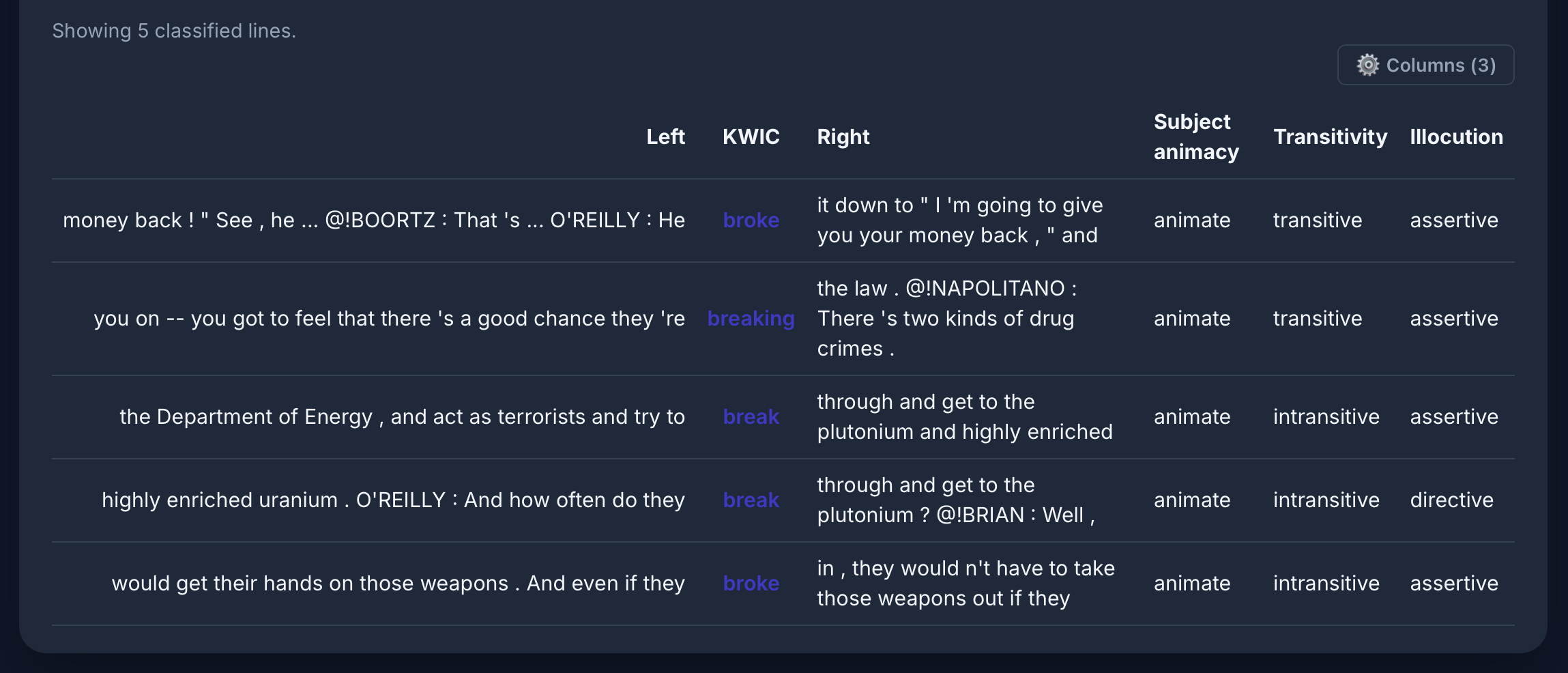
Causative alternation für [lemma="break" & tag="vv.*"] im COCA:
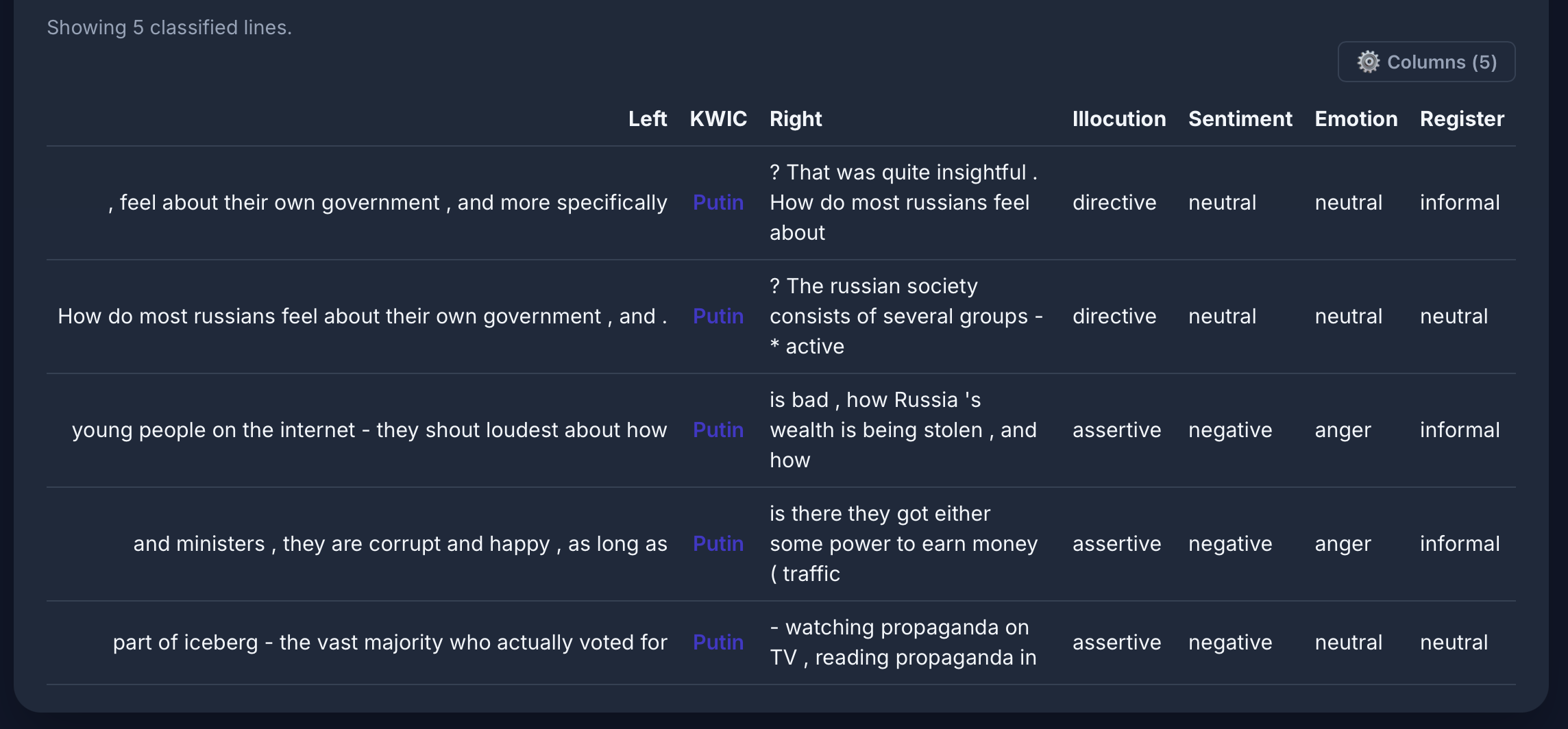
[word="Putin"] im Russian Reddit-Korpus:
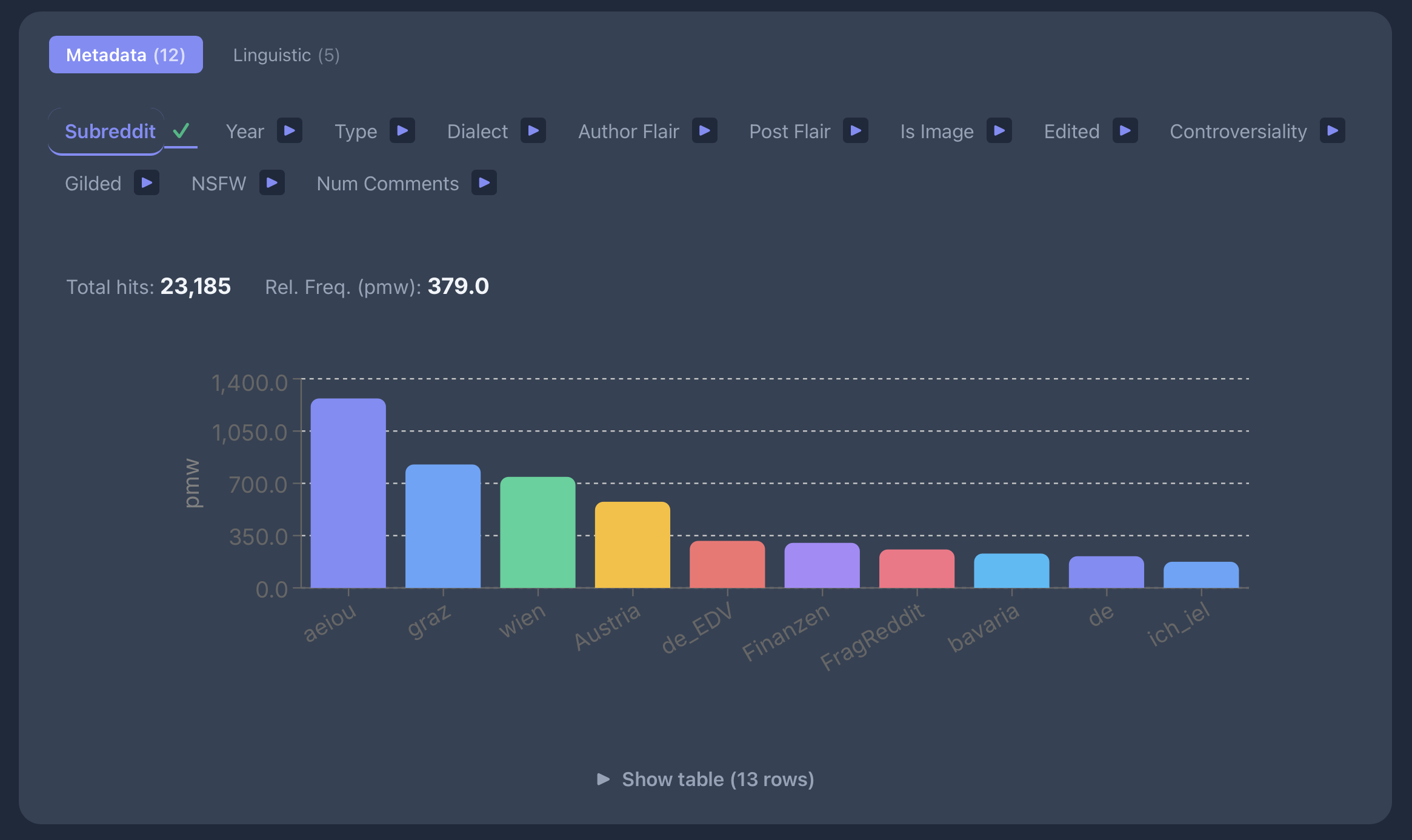
Linguistische Features
Lexikalische Variation
Frequenz von [word="eh"] im deRed-Korpus.
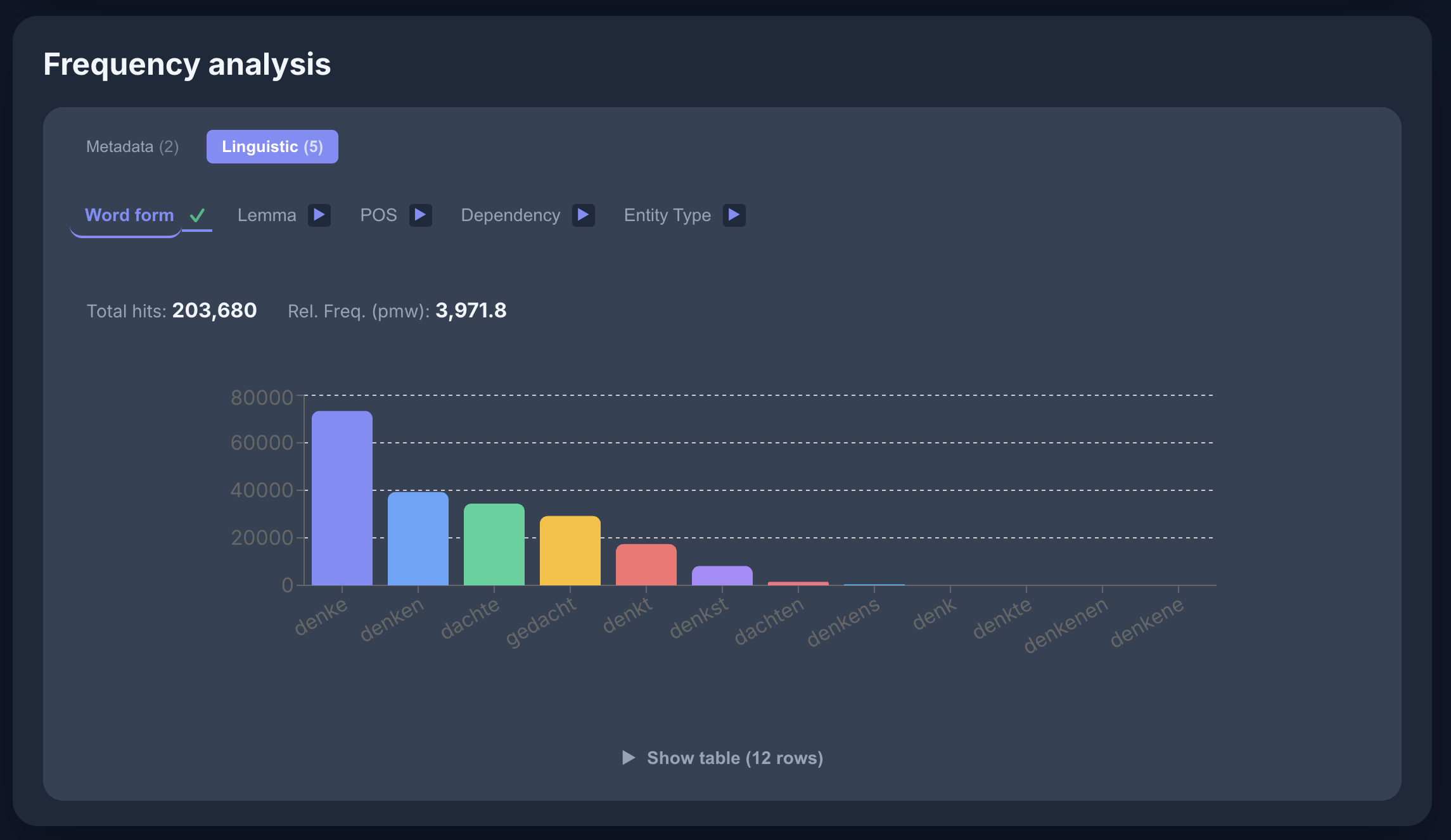
Lemmatisierung
Wort-Formen für [lemma="denken"] im GeRedE-Korpus:
Morphological Parsing
[morph=".Gender=Masc."] im GeRedE-Korpus:
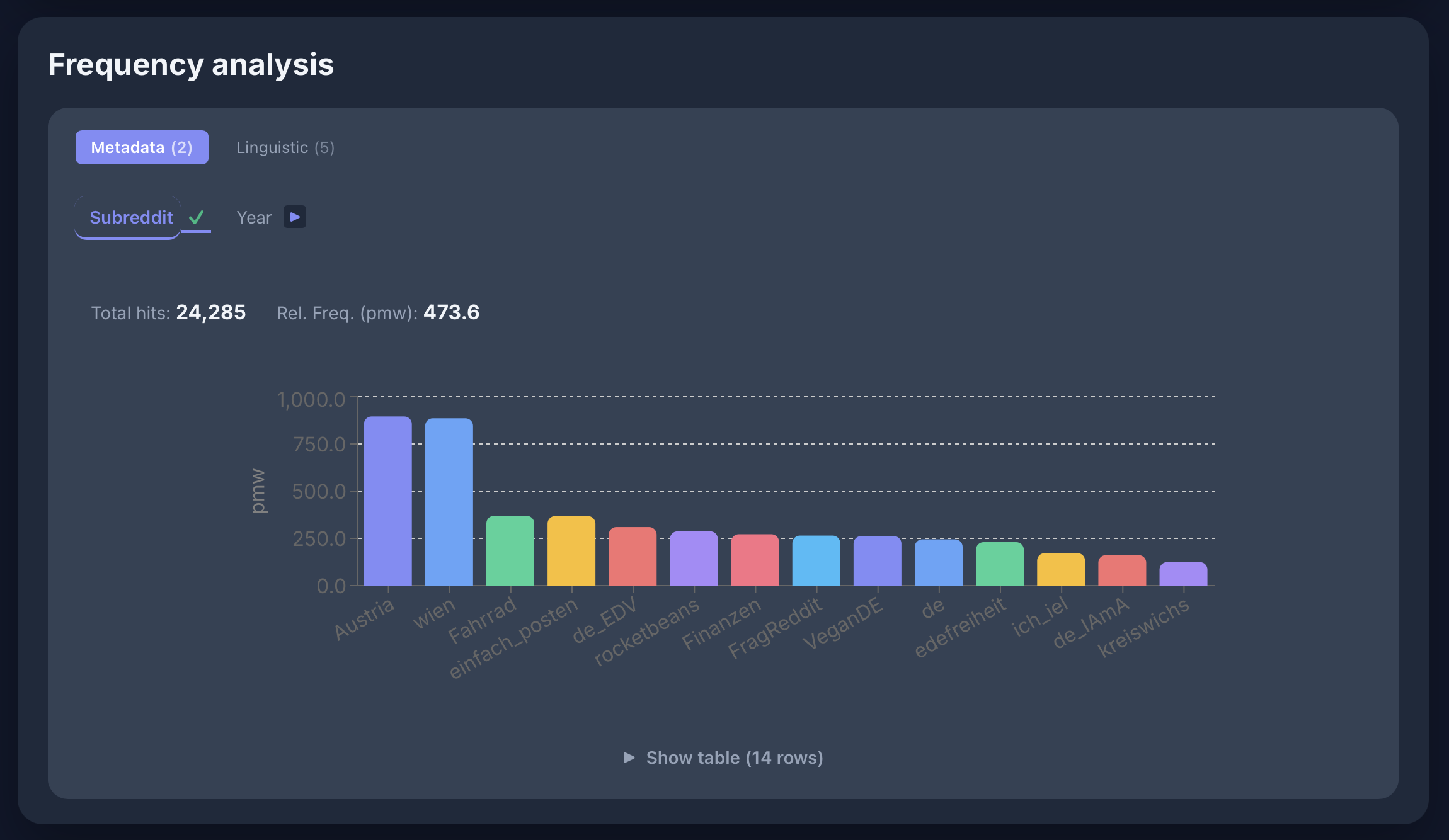
Frequenzanalysen
Frequenz von [word="eh"] zwischen Communities im GeRedE-Korpus:
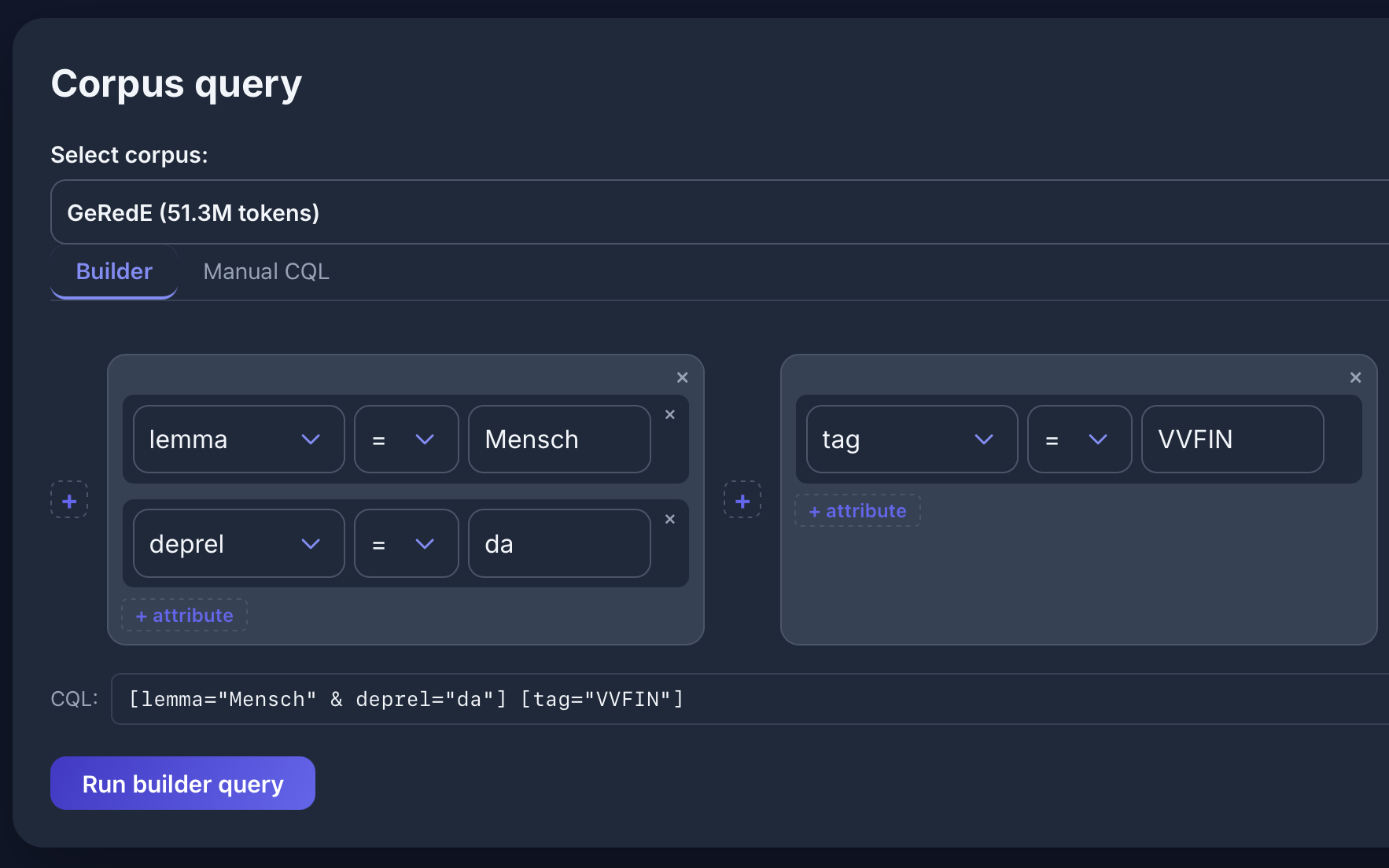
Dependenzen
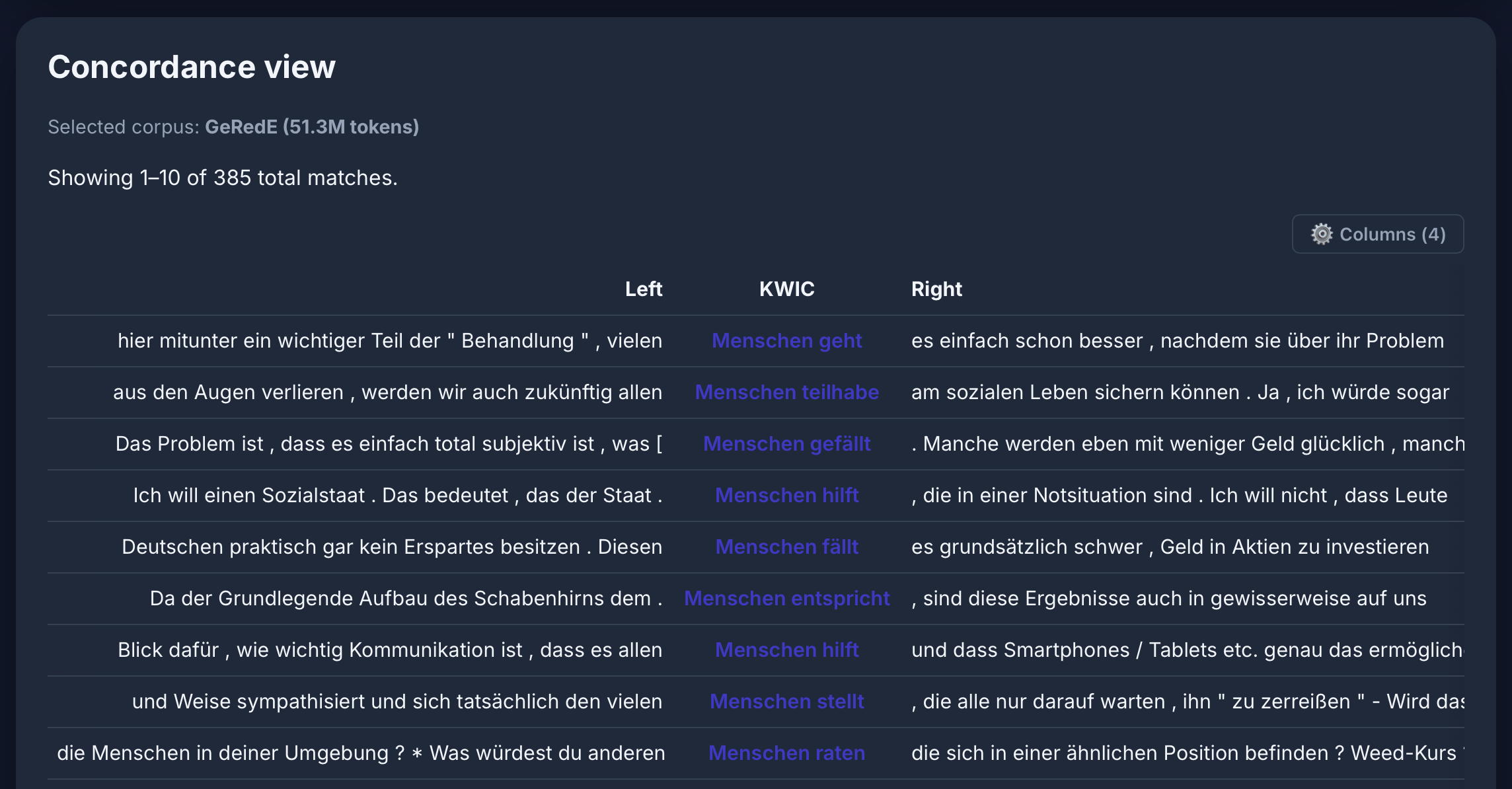
[lemma="Mensch" & deprel="da"] [tag="VVFIN"] im GeRedE-Korpus:
Relativsätze: Bairisches wo
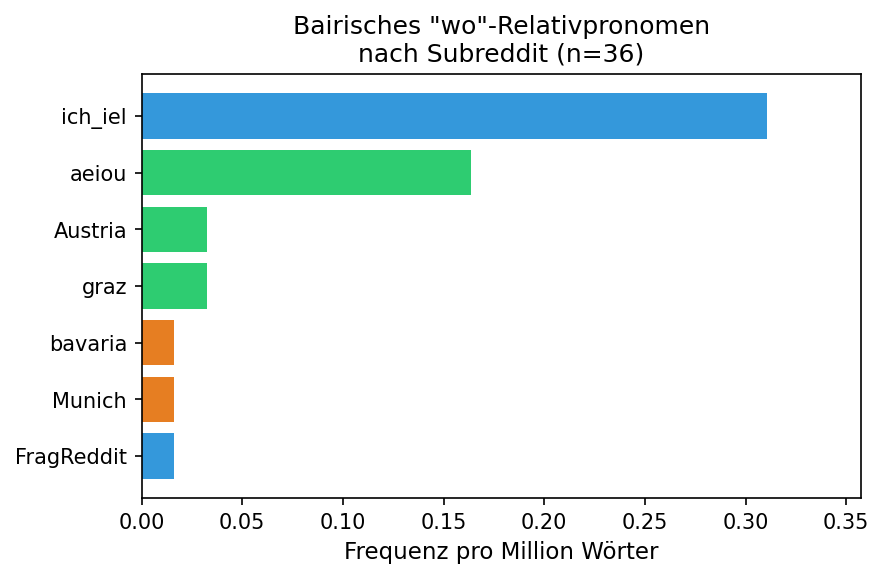
Beispiele:
- Der oane der wo beim Starmania gsungen hat
- die wo denken das es echt is
- Der Sturm der wo des kloane Ding ausradiert
- des wo ummalieng sig hau i des weg
- wos wo i üban durchschnitt bin
Memes
ich_iel (Standarddeutsch)

| Phrase | Treffer |
|---|---|
| Hurensohn | 7.121 |
| Sprich Deutsch | 365 |
| meine Kerle | 165 |
aeiou (Österreichisch)

| Phrase | Treffer |
|---|---|
| ned | 13.546 |
| Oida | 5.046 |
| Piefke | 714 |
Semantische Analysen
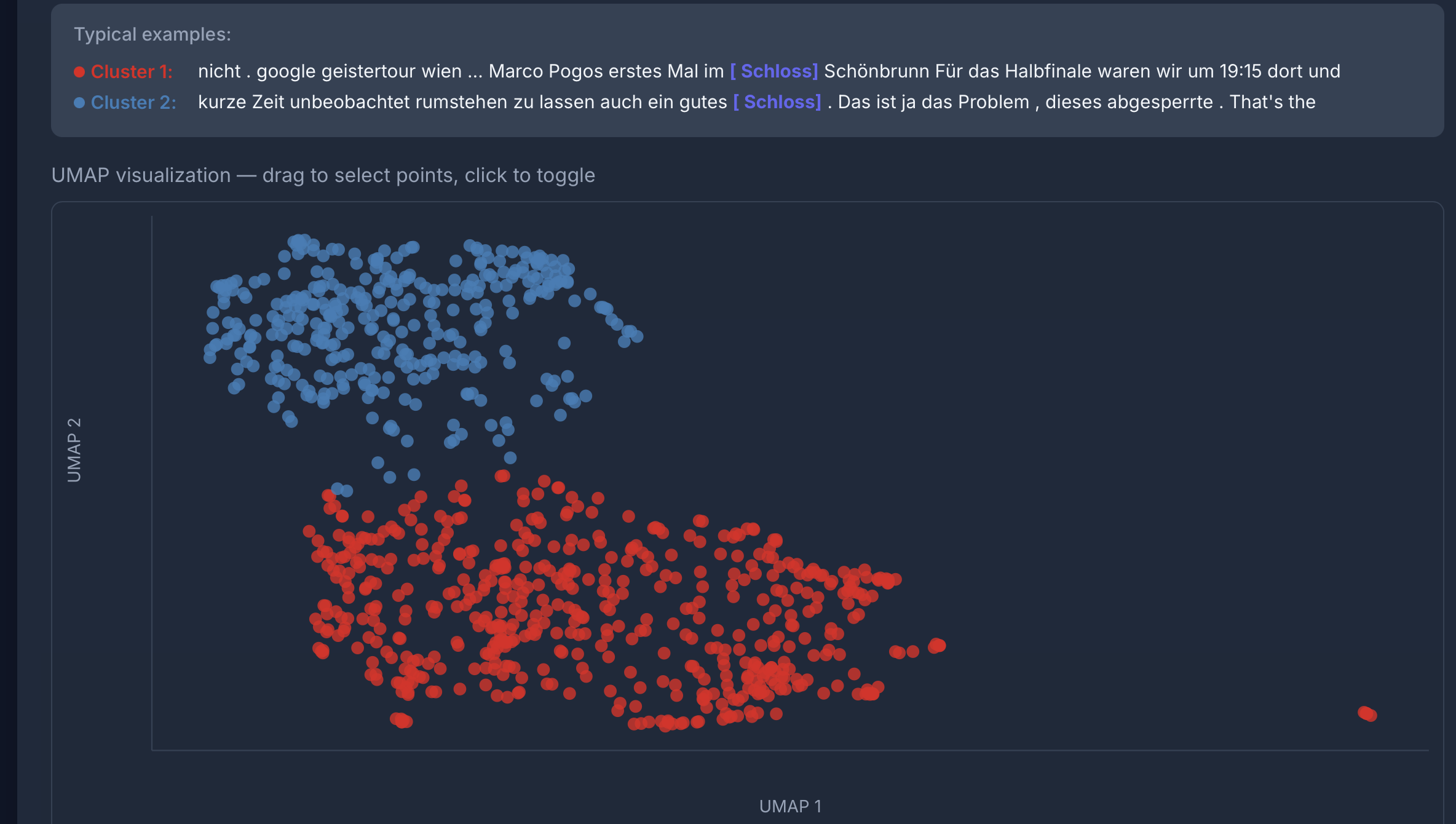
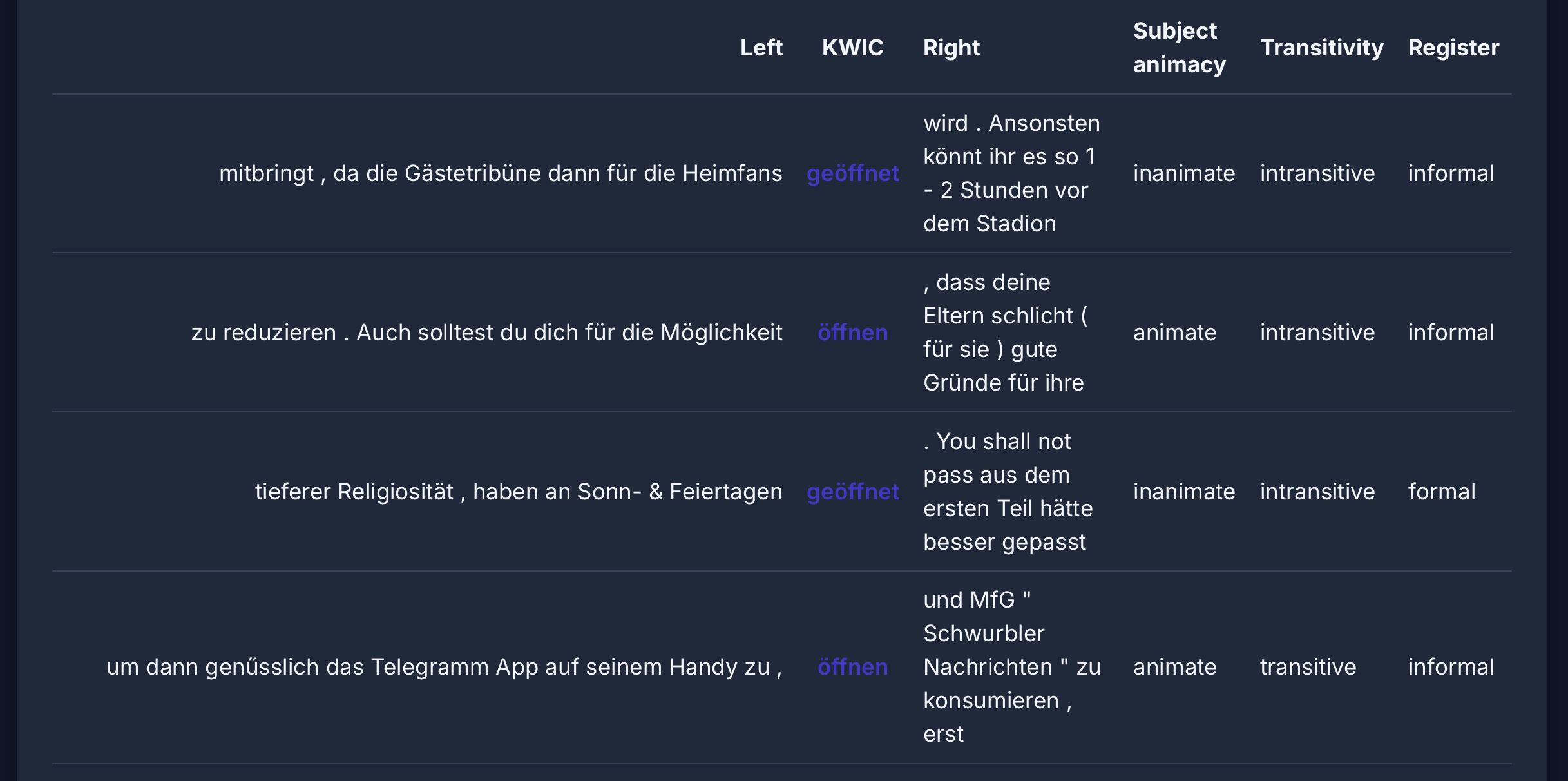
LLM-Klassifikation
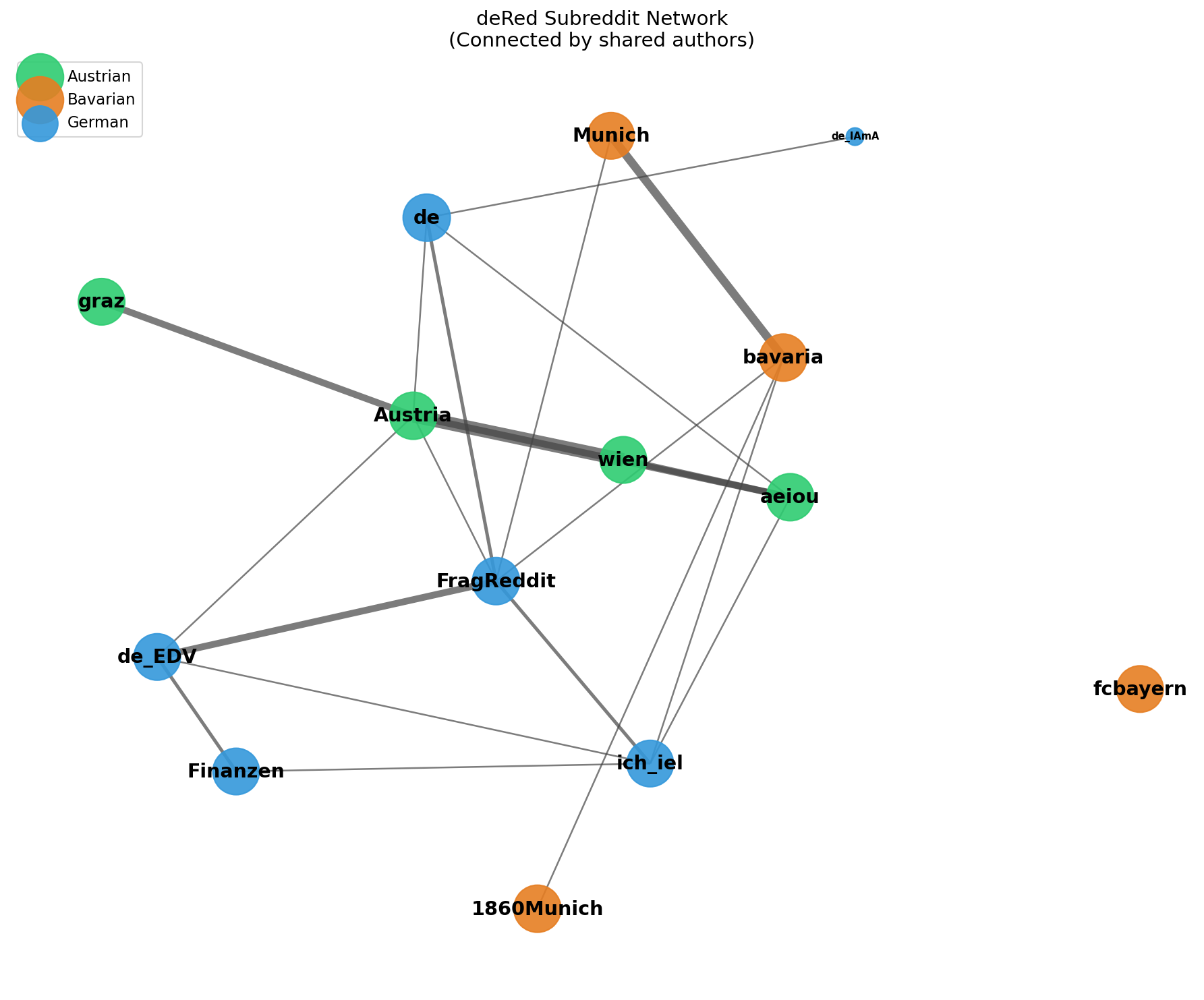
Subreddit Network
User Interaction Network (r/Austria)
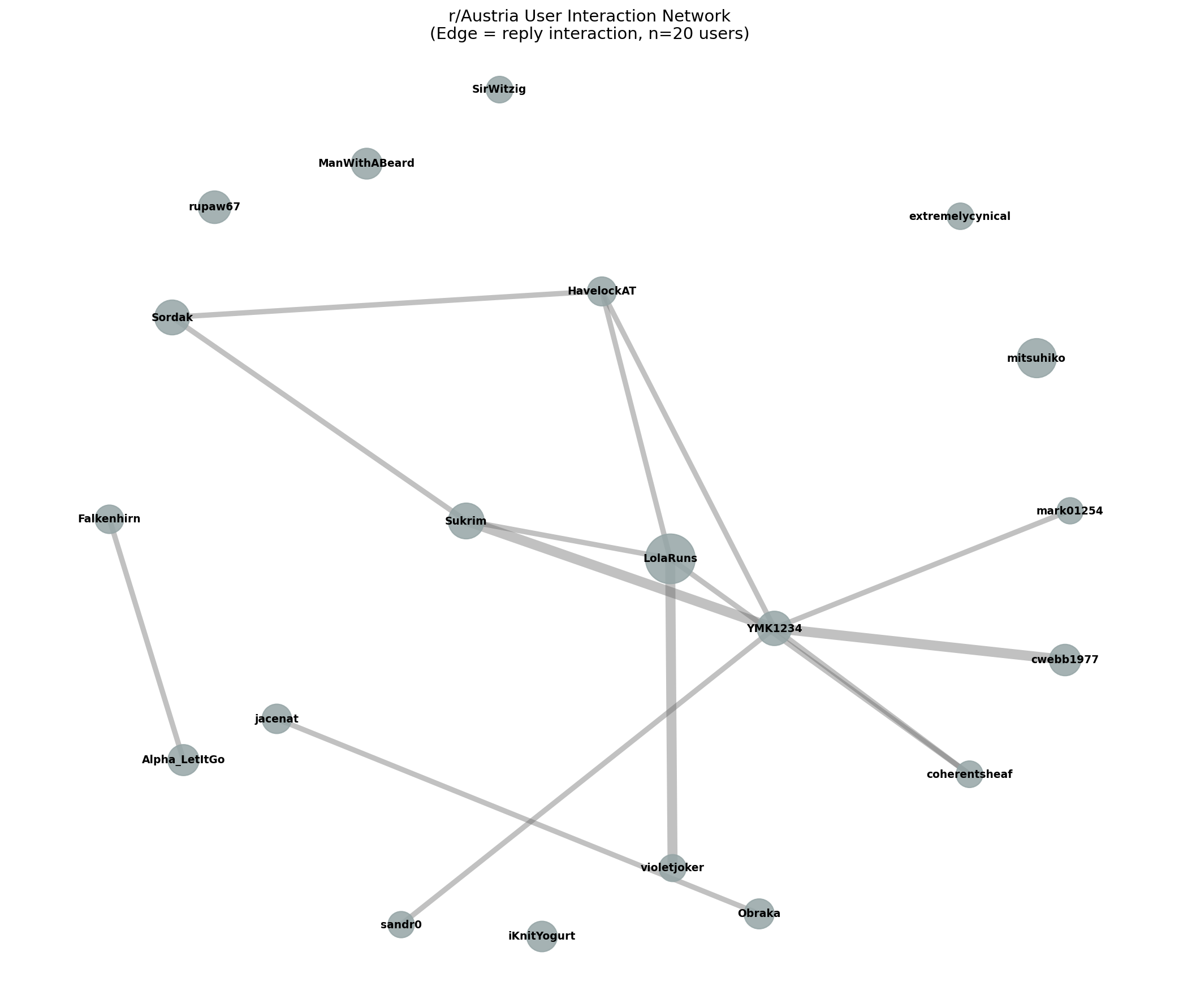
Social Network Analysis