Munich Corpus Lab
Graduiertenschule Sprache & Literatur, LMU München

Die Munich Corpus Lab App
https://www.wuerschinger.org/mcl
Benutzername: lipp@lmu.de
Passwort: Sch3ll!ng1860
React interface
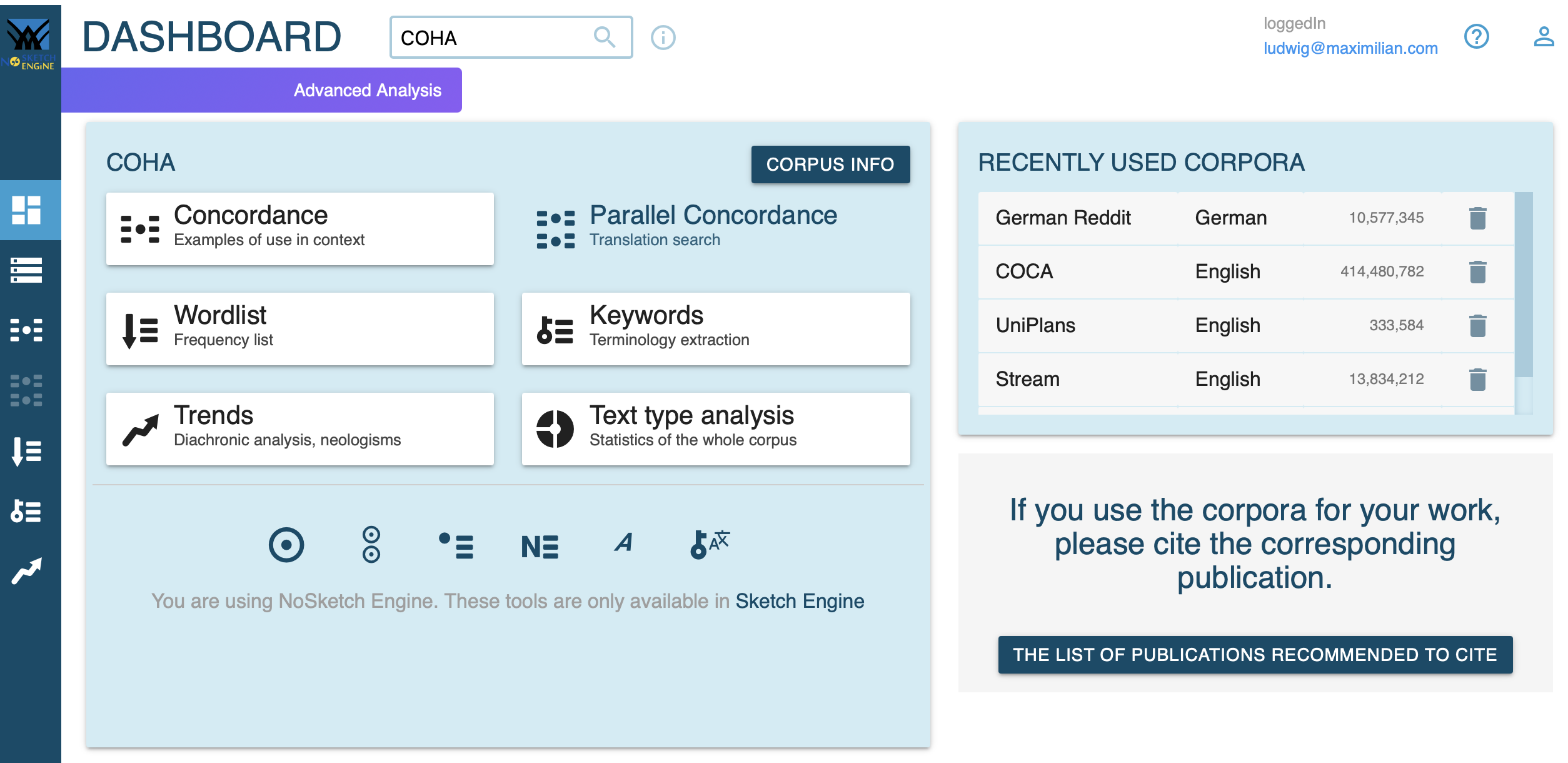
No Sketch Engine interface
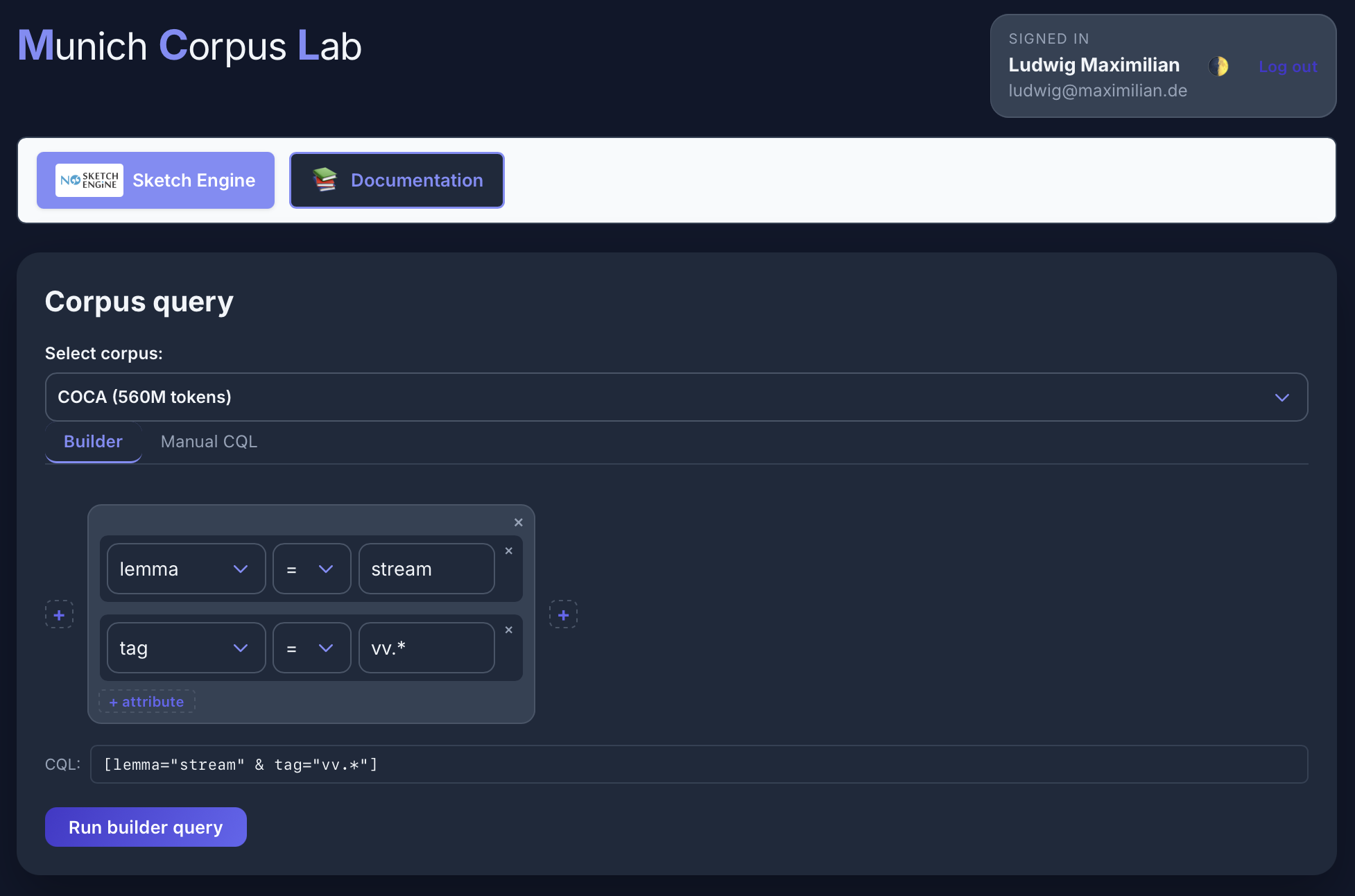
Query Builder

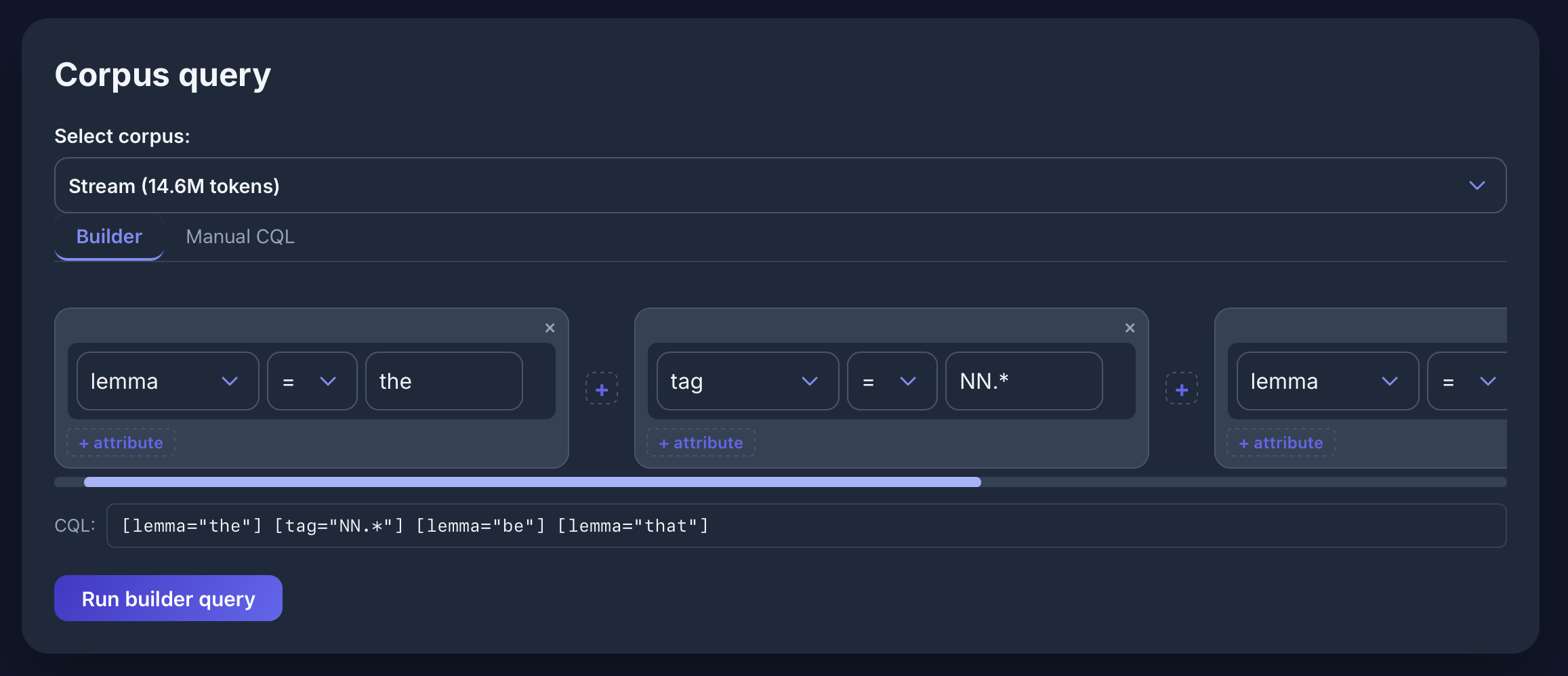
Concordance View
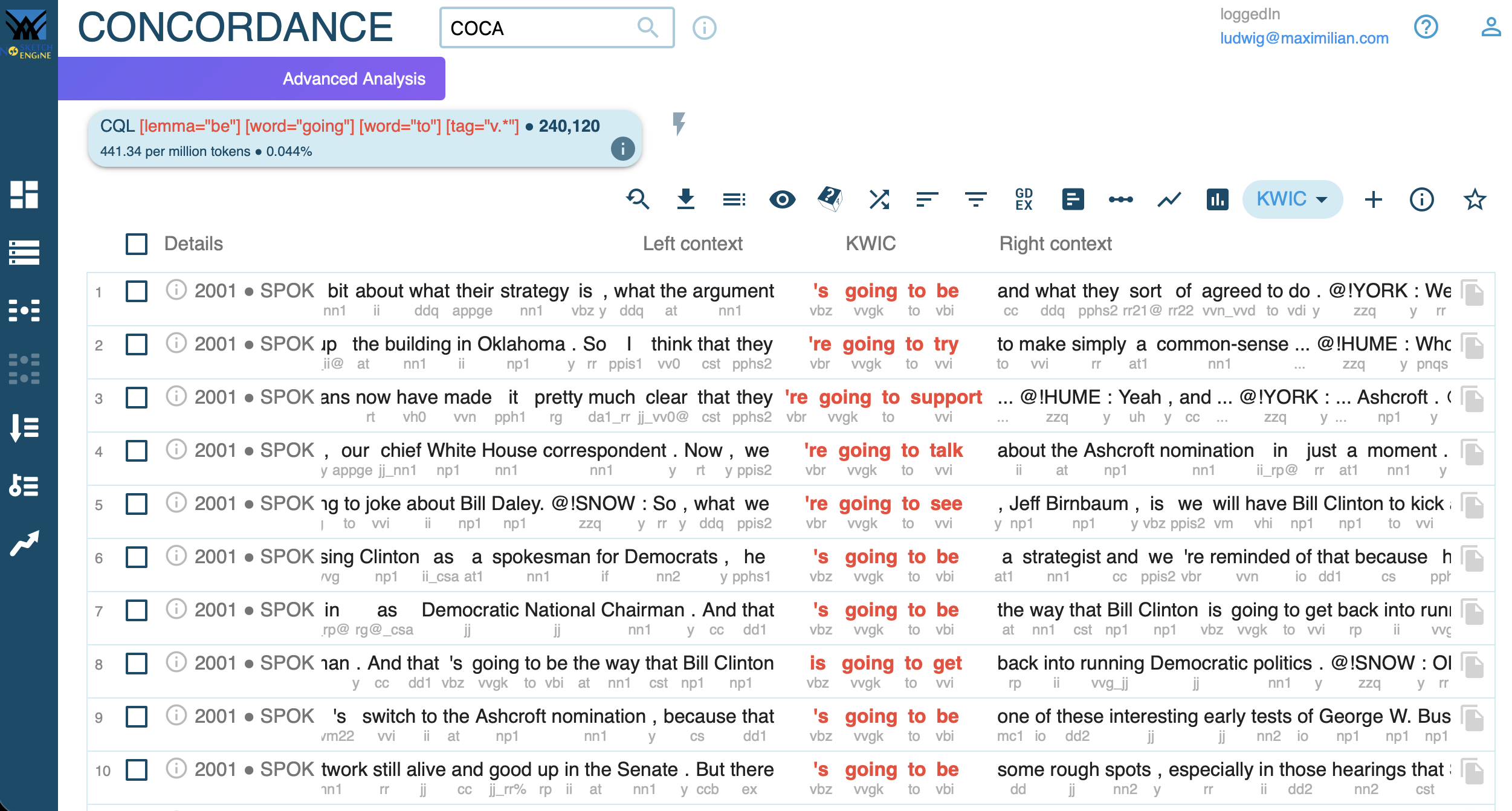
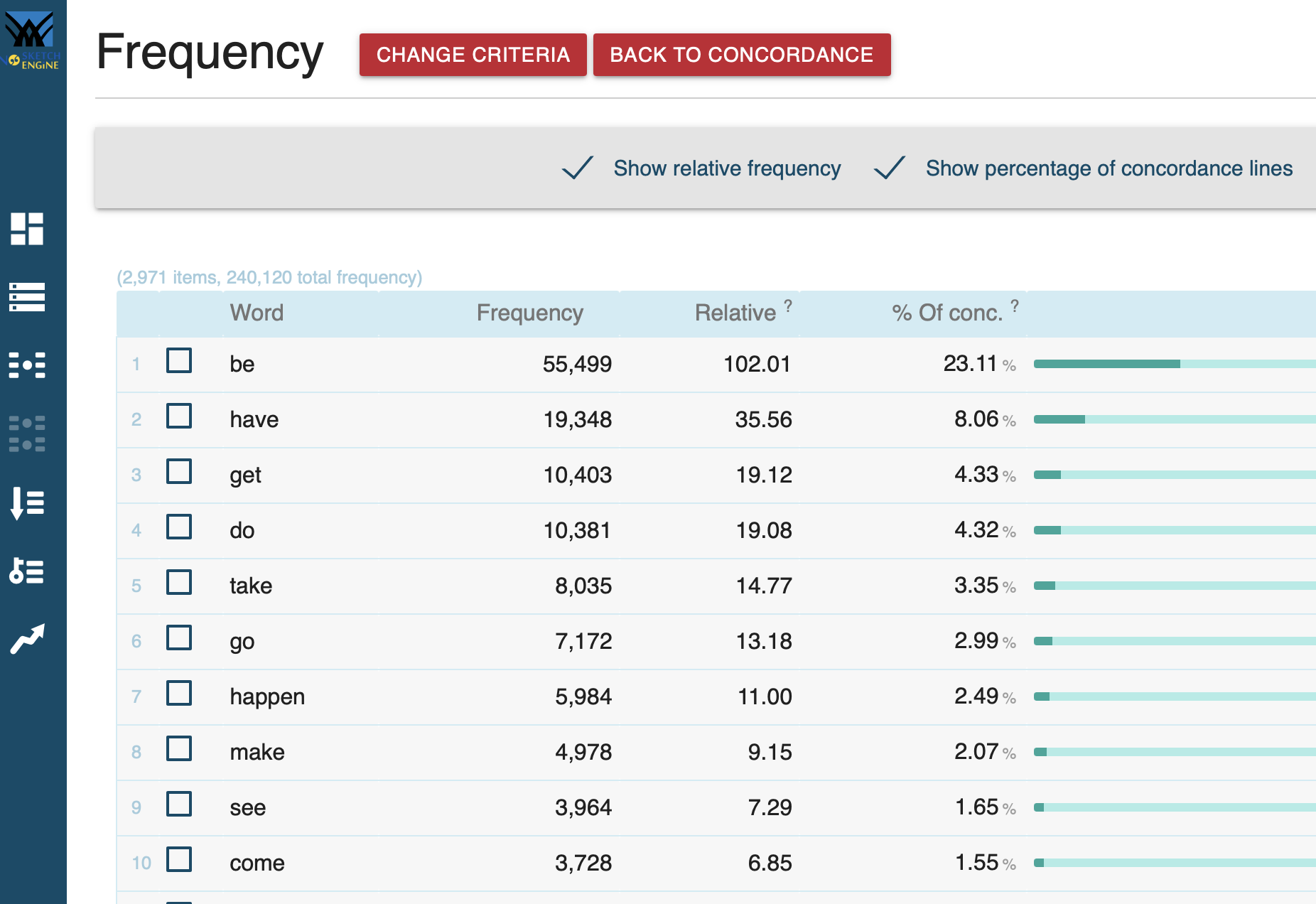
Frequenzanalyse
Verb in [lemma="be"] [word="going"] [word="to"] [tag="VB.*"] im Stream-Korpus:
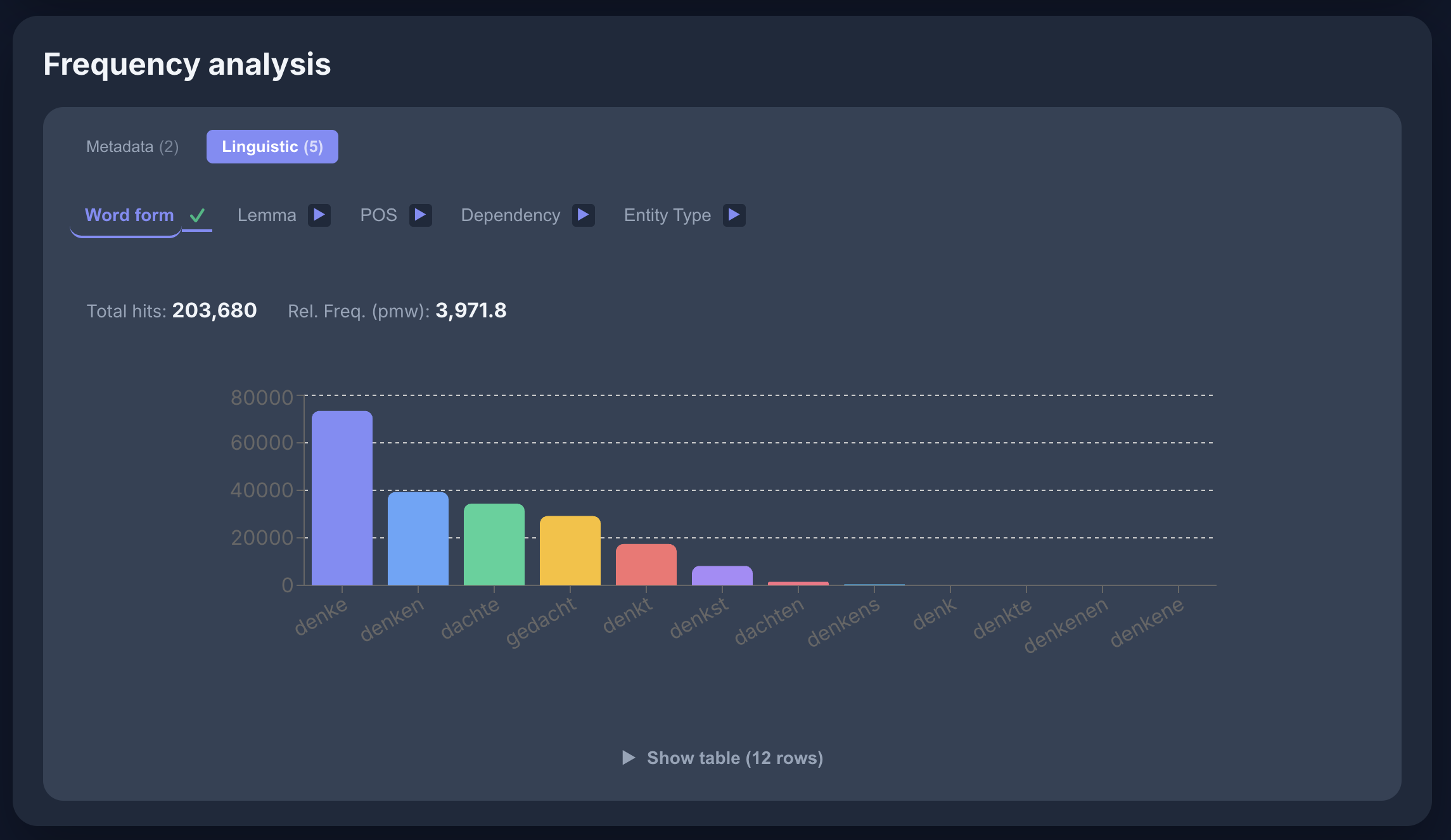
Wort-Formen für [lemma="denken"] im GeRedE-Korpus:
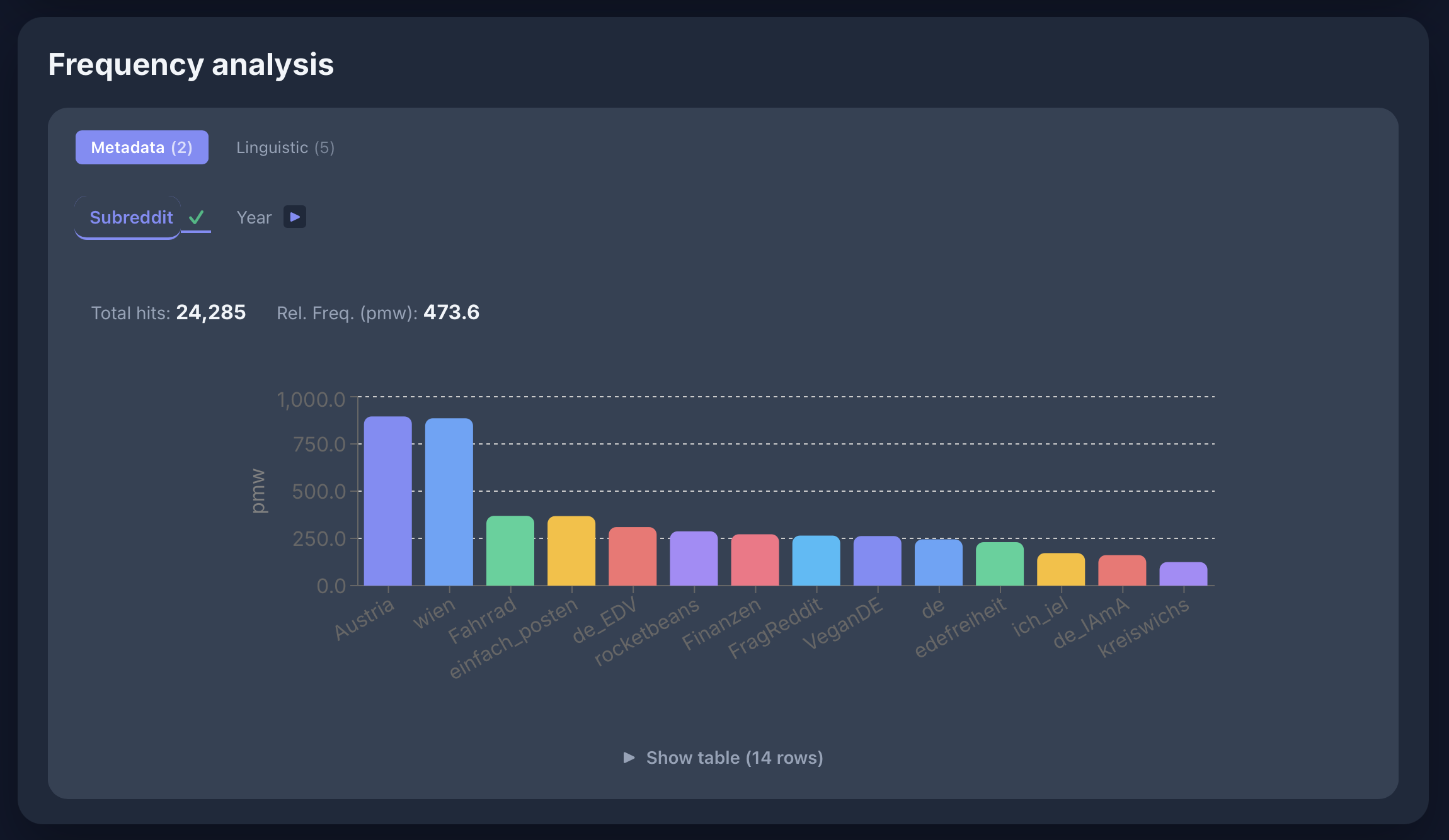
Frequenz von [word="eh"] zwischen Communities im GeRedE-Korpus:
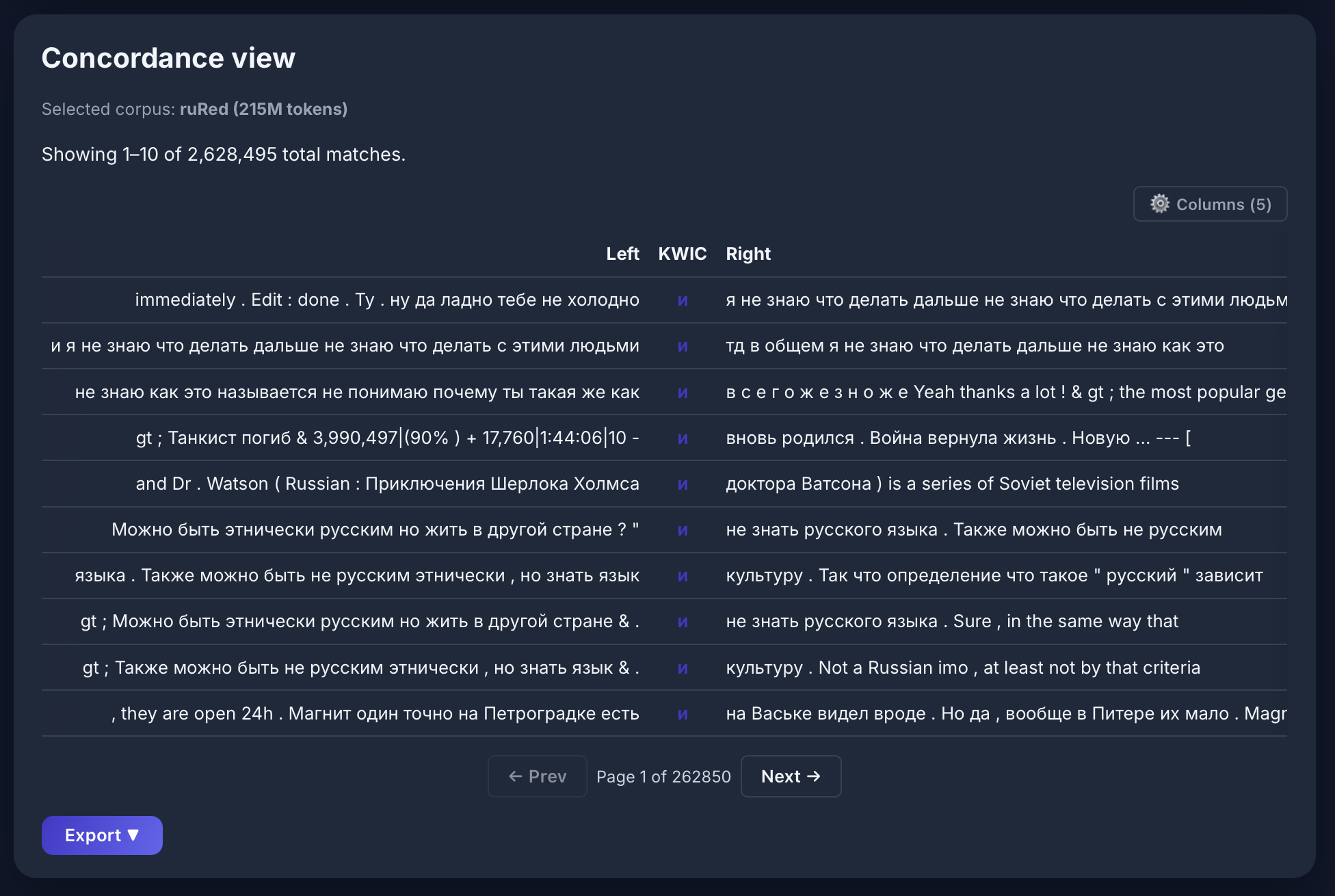
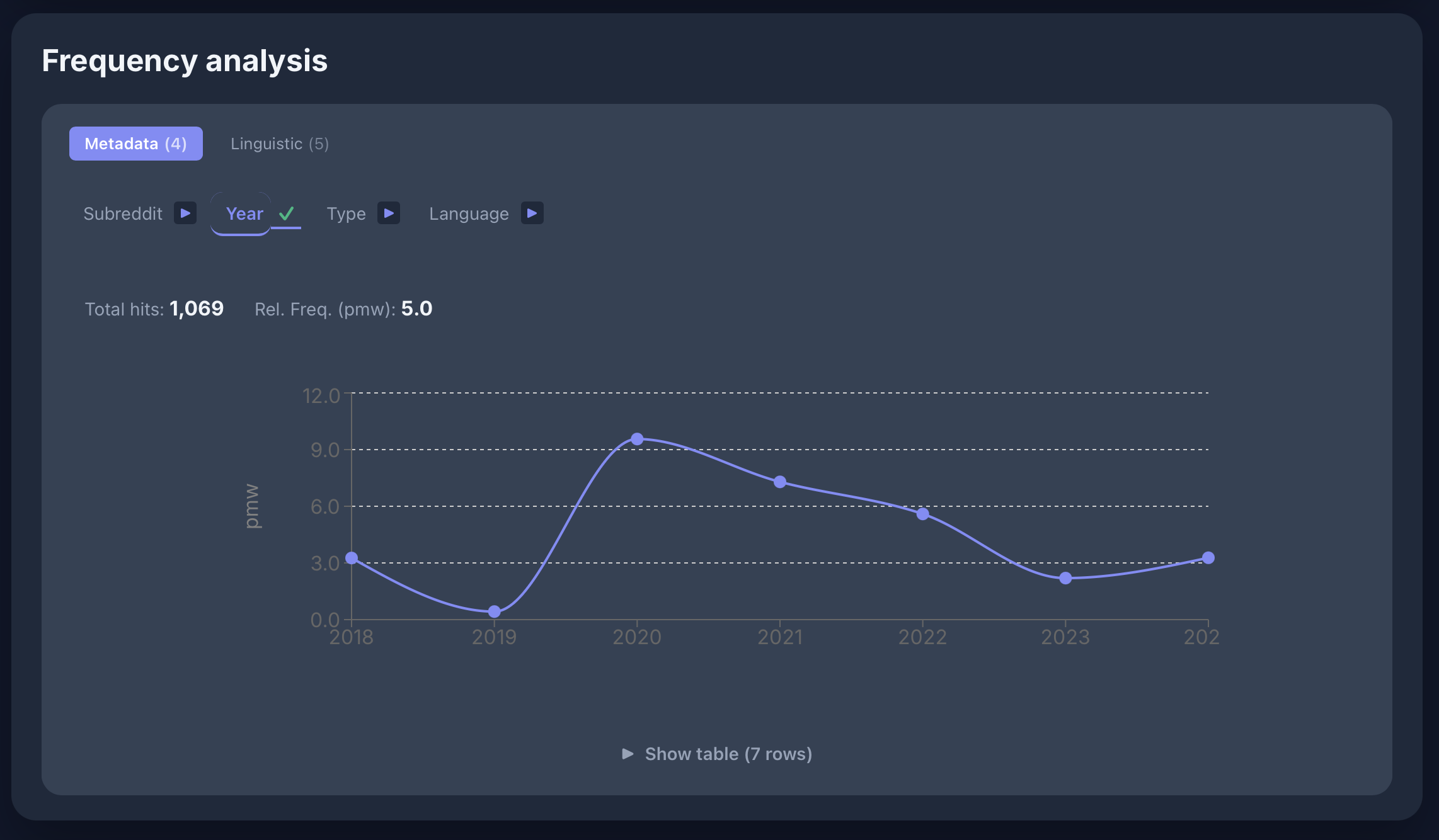
[lemma="virus"] im Russian Reddit - Korpus:
Dependenzen
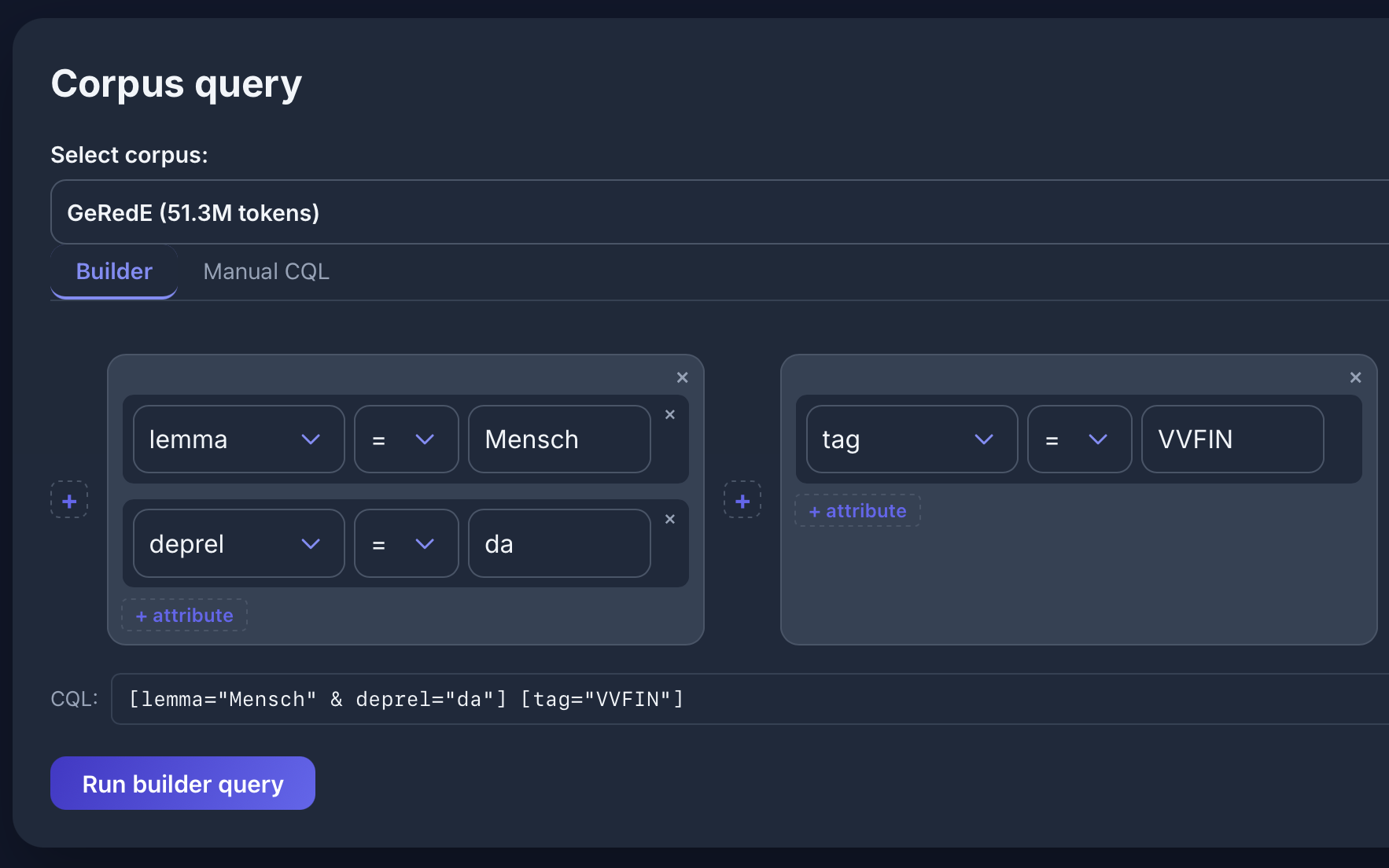
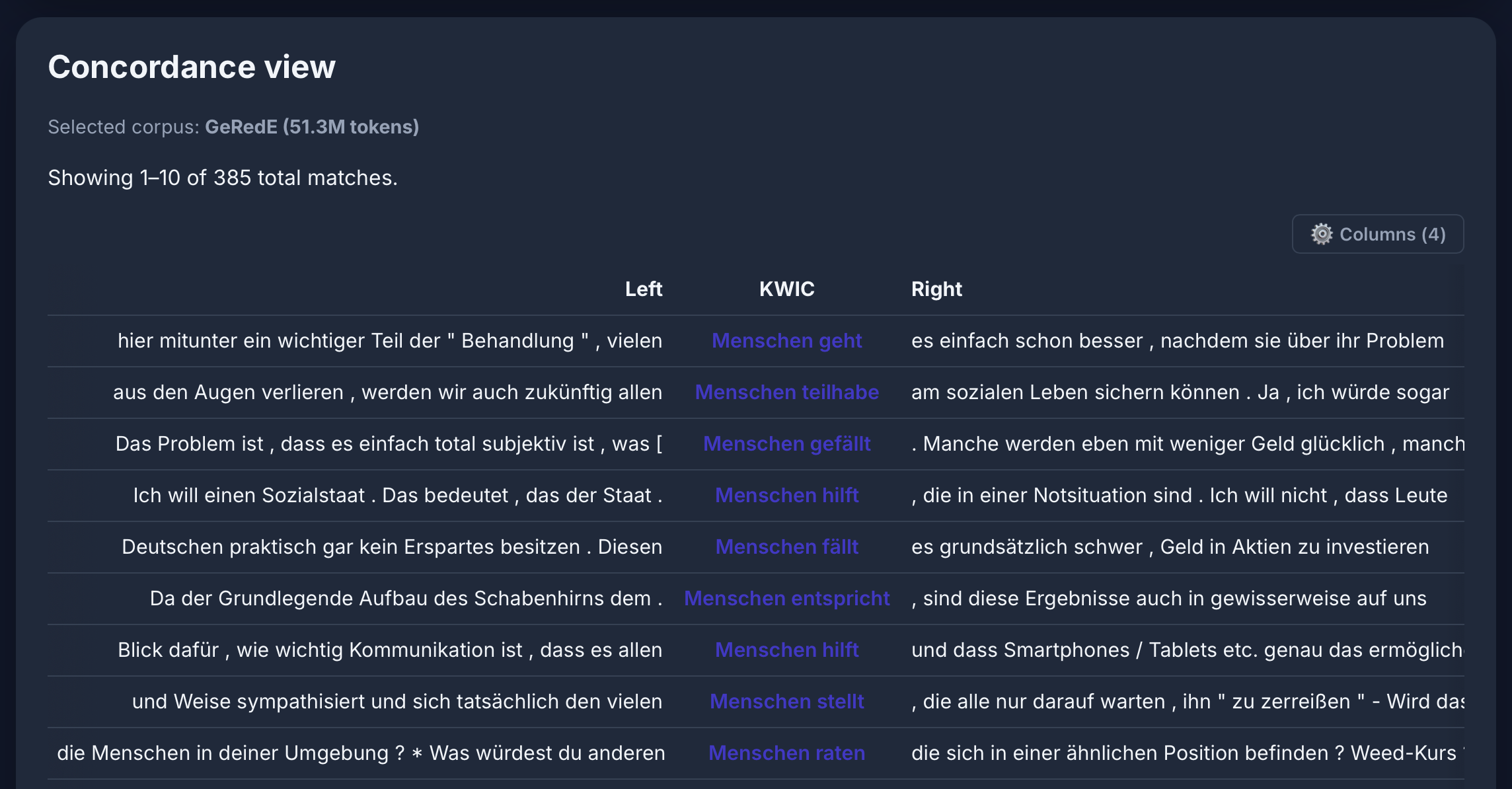
[lemma="Mensch" & deprel="da"] [tag="VVFIN"] im GeRedE-Korpus:
Named Entities
[ent_type="GPE" & deprel="dobj"] im UniPlans-Korpus:
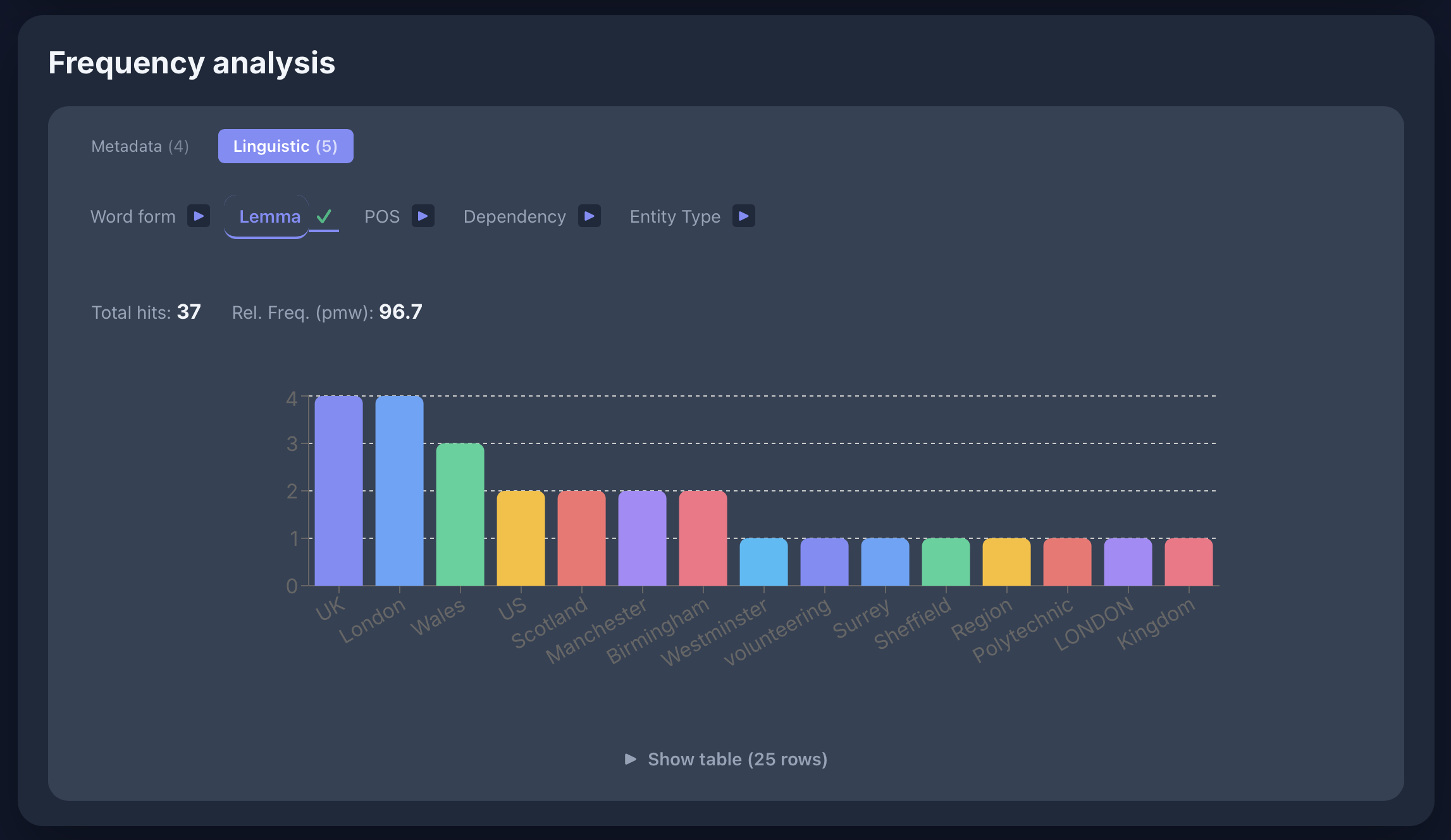
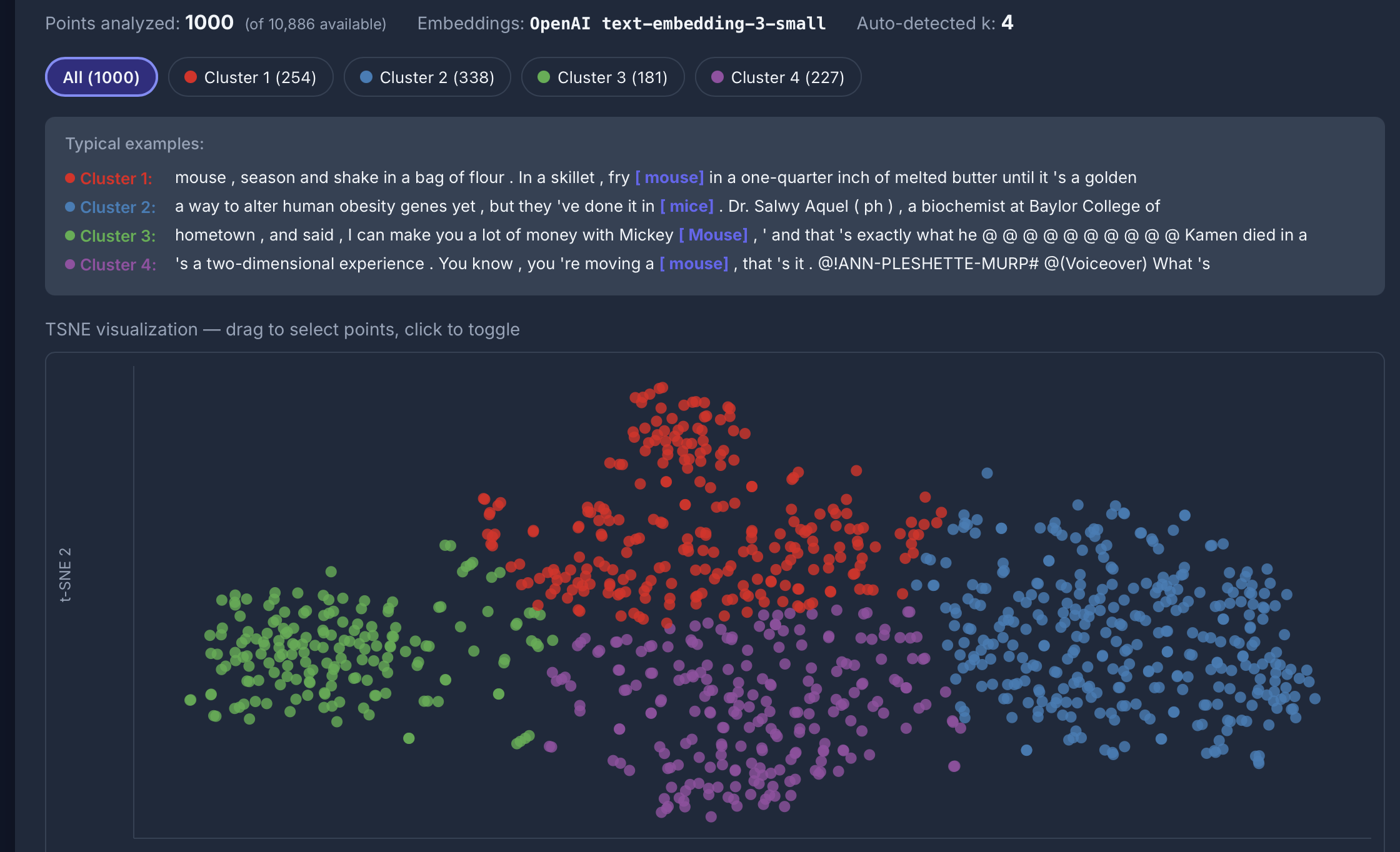
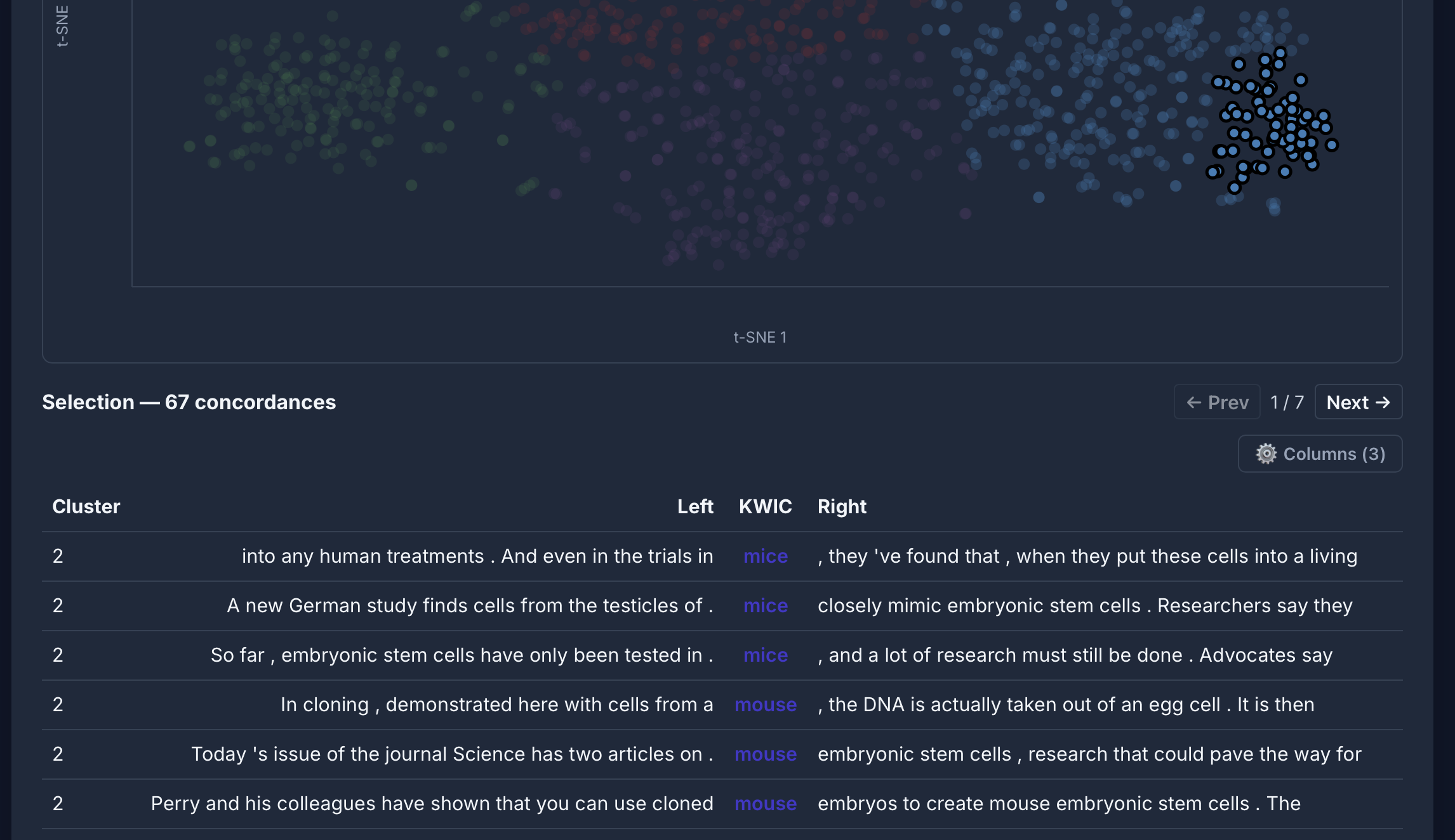
Semantic analysis
[lemma="mouse"] im COCA:
LLM classification
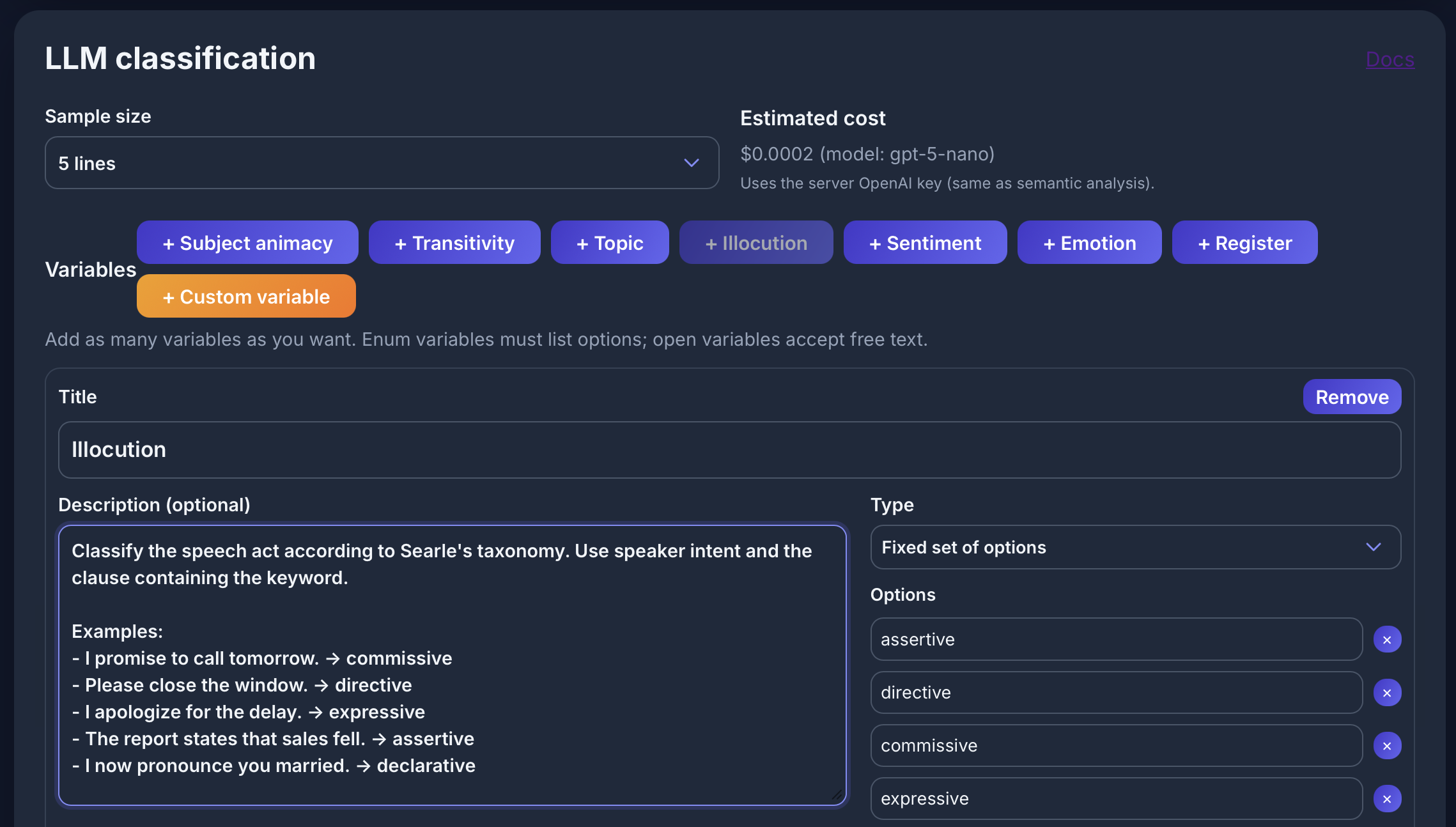
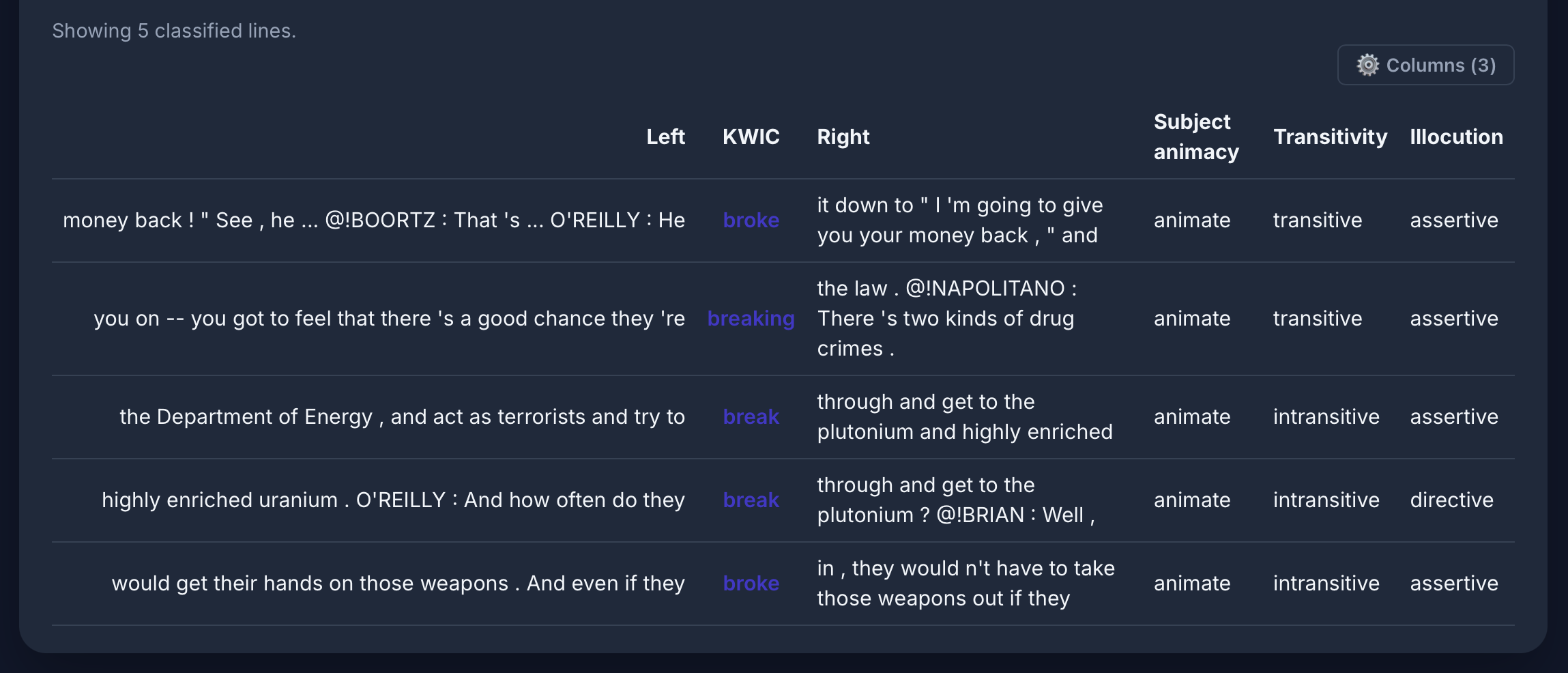
Causative alternation für [lemma="break" & tag="vv.*"] im COCA:
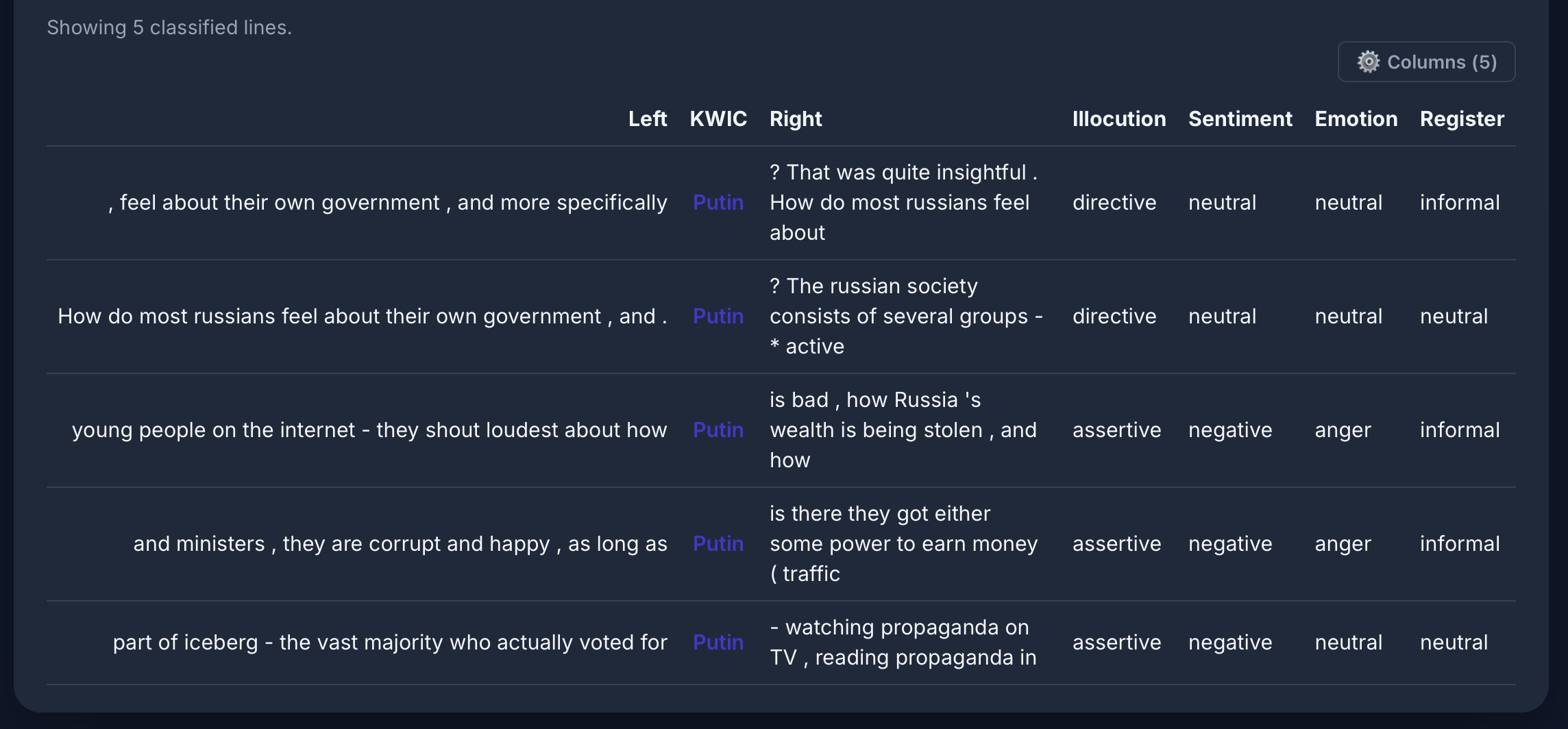
[word="Putin"] im Russian Reddit-Korpus: